FPN
This semantic segmentation model also makes use of the encoder-decoder modules. A regular convolutional neural network with a fully connected layer is used as the encoder. The encoder extracts the low-resolution feature map.
Then, this feature map has to go through a decoder module to produce a segmented image of the original resolution. The decoder module makes use of the Feature Pyramid Network, FPN.
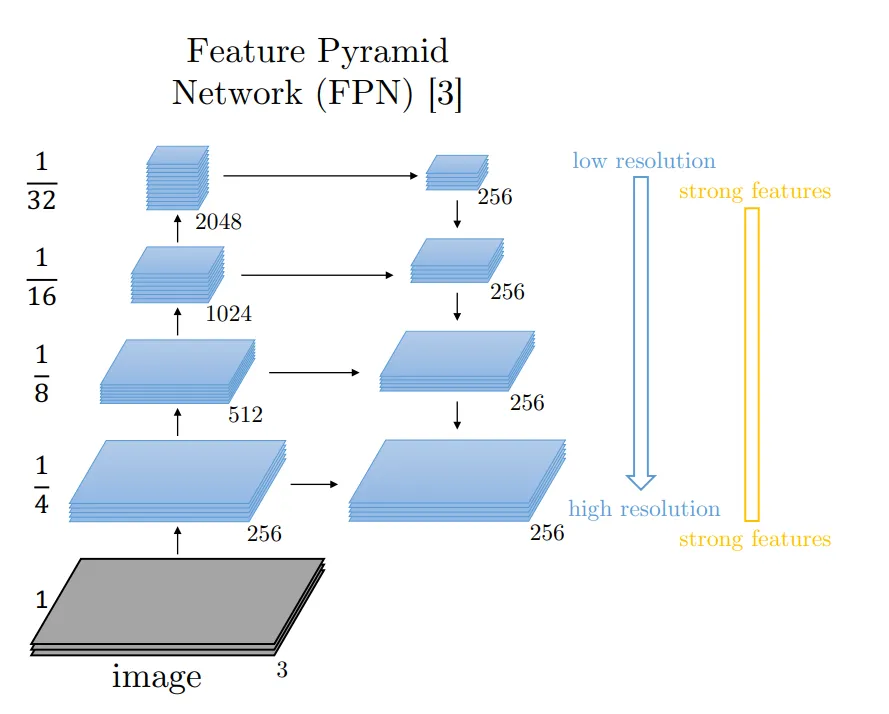
The diagram given above depicts the inner working of the FPN at a very high level. The bottom-up path is the encoding part where the image is converted to a low-resolution feature map.
For the decoding part, the feature map combines these low-resolution feature map that has semantically strong features, with the previously upsampled image that has semantically low features.
Due to this, the feature pyramid has rich semantic features at all levels.

Now, since all the levels are rich in semantic features, they can be combined to produce the final segmented image. Note that the above picture depicts an additional 3X3 convolution from the 2nd column to the 3rd column. This is done to reduce the aliasing effect of upsampling.
Parameters
Encoder Network
The network used in the bottom-up path in the given diagram is the encoder network. Here ResNet or Efficient Net can be used.
Depth of Encoder Network
This defines the depth of the encoder network. Note that deeper networks produce results with lower error but are more computationally expensive.

Source
Encoder Network Weight
It is the weight by which the encoder network is initialized. The weights here are the ones that were found on the ImageNet dataset of the respective architectures.
Weights
They are the weights by which the entire FPN architecture is initialized. Here, it is initialized randomly.
Dropout
It is the spatial dropout rate used in FPN.
When the feature maps are strongly correlated to each other, regular dropout of the layers will not cause regularization and only results in a learning rate decrease. Spatial dropout is used to drop entire feature maps. This regularizes the network with strongly correlated feature maps and makes the training computationally efficient.