Containerized Deployment
Previously explained frameworks should be running well on your machine, but you might run into issues when you try to deploy to another environment like a server to serve the application 24/7. In most cases, this is because your cloud environment is built on other hardware and using a different OS with different drivers compared with your local machine. To avoid this pitfall, you can containerize your model.
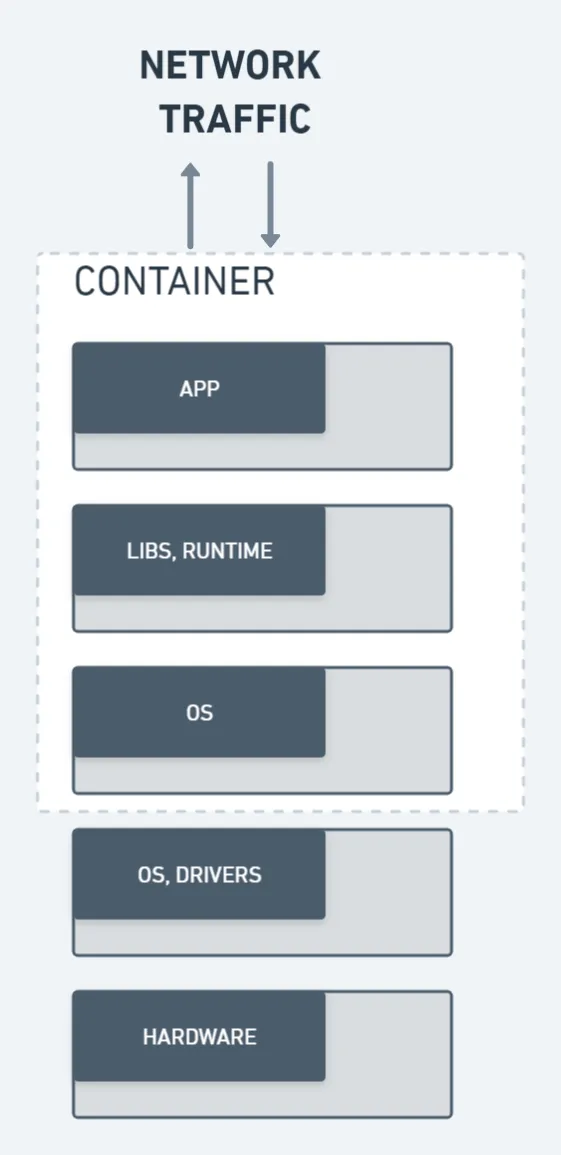
Deployment using containers allows you to benefit from management software that simplifies launching and updating your application.
Features of Container Deployment
- Run a large number of individual applications on the same number of servers.
- Deliver ready-to-run applications in containers that contain all of the code, libraries, and dependencies needed by any application.
- Make application deployment and management easier and more secure.
- Modify an application and run it anywhere in an instance.
One of the pros of using container deployment is reproducibility. For example, if you take a typical model pipeline, you have a set of packages and dependencies that are involved when you use open source libraries, such as a certain version of numpy, and pandas, scikit-learn and/or tensorflow.
Practical Use case
Once the data scientist has trained the model, they must tell a software engineer to replicate the exact environment with the same libraries and version as the model was trained on the first time, which is a time-consuming task that must be documented and passed on to the deployment team. But with containers, we can package the code as well as the dependencies into a containerized package and then ship it on to the software engineering team so they can deploy it seamlessly without any handholding from the data science team.
It significantly reduces the time required to deploy a model which helps in reducing the time to generate insights. Also, while productizing your AI model, you may put everything in a container and ship it to your client, who can then just deploy it and get started rather than you providing the client, installation instructions to follow.
The common steps for Machine Learning Using Docker are:
- Training the ML model.
- Saving and exporting the ML model.
- Creating a Flask app that includes the UI layer.
- Building a custom Docker image for the app.
- Running the app using a Docker container.