Attribute Prediction
Computer Vision (CV) is a scientific field that researches software systems trained to extract information from visual data, analyze it, and draw conclusions based on the analysis. The area consists of so-called CV or vision AI tasks. Each task is unique and incorporates techniques and heuristics for acquiring, processing, analyzing, understanding the data, and extracting various details from it. On this page, we will:
- Cover in-depth the Attribute Prediction vision AI task;
- Understand the difference between Attribute Prediction and Multi-Class Classification;
- Research the real-life applications of Attribute Prediction;
- See features that CloudFactory offers for streamlining an Attribute Prediction task.
Let’s jump in.
What is Attribute Prediction in Machine Learning?
As the name suggests, the Attribute Prediction task is concerned with detecting the attributes of the objects in the image.
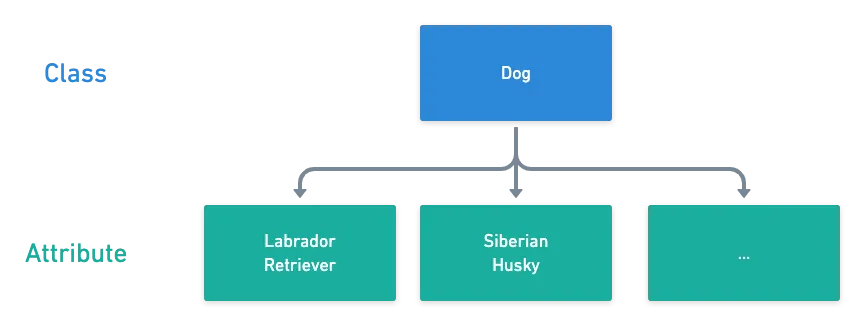
Visual attributes contain essential information about the objects and the scene overall. One object may possess several attributes, for example, color, material, geometric properties (size, shape), position in space, state (jumping, moving, laying), and many more.
Attribute Prediction can also be referred to as a Multi-Label Classification problem as it also focuses on predicting all the relevant attributes of a given object.
Attribute Prediction explained
Attribute Prediction (AP) is a Classification task that allows you to predict one or more labels related to the object. This means you can assign multiple attributes to the same object in the training data. The image below shows how an example of input and output can look for the AP task.

GT stands for the Ground Truth.
Source
The general Attribute Prediction algorithm in ML is as follows:
- You feed the model some prelabeled data as input;
- The model returns the probability vector as an output (for example, [0.1, 0.35, 0.7] representing the probabilities of attributes 1, 2, and 3);
- You analyze the obtained vector based on standard heuristics or your own logic and formulate the final prediction.
In general, Attribute Prediction can be applied in the following cases:
- Whenever you want to assign an object to many classes simultaneously;
- Whenever you want to have a more complex taxonomy, for example, a second-degree one.
Source
Source
Attribute Prediction Vs. Multi-Class Classification
As we have established earlier, the Attribute Prediction task may interchangeably be called the Multi-Label Classification task. Such a name is frequently used by researchers in academic papers and often confuses those unfamiliar with the topic.
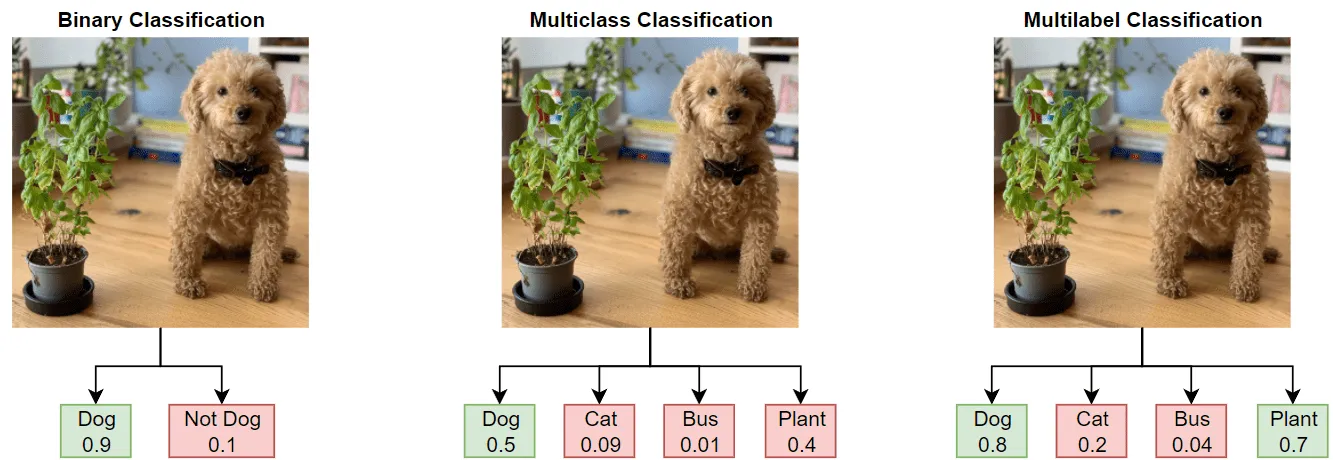
Another common CV technique is Multi-Class Classification. Even though these two sound similar, they refer to different tasks.
- In Multi-class Classification, each input can have only one label as an output. For example, according to this task, a dress can be only black & blue or white & gold, and not both simultaneously.

Source
- On the other hand, in Attribute Prediction (or in Multi-Label Classification), you can assign more than one label to the same object simultaneously. For example, a movie can be classified as horror, thriller, and detective at the same time, and these labels are not mutually exclusive.
Attribute Prediction real-life applications
- Image Captioning - describing the content of an image with words in a natural (human) language. Detecting and describing different objects, states, and actions in the image requires a fine-tuned Attribute Prediction;

Source
- Visual Question Answering (VQA) - in this CV task, we give a text-based question about the image as an input, and the system should provide an answer as an output;

Source
- Genre classification - for example, in movies, songs, literary works, and many other domains, an input can be assigned more than one genre at a time;
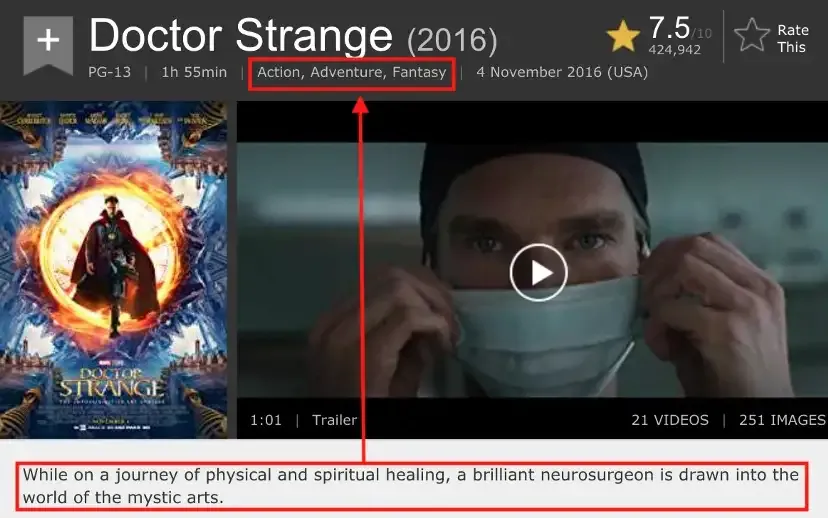
Source
- Image Retrieval - finding images similar to a query image;

Source
- Image Search - finding images in the database containing the specified attributes (for example, color, material, or shape).

Source
Attribute Prediction datasets
We must mention that only a few datasets are devoted to Attribute Prediction exclusively. This might be partially explained by the fact that objects in the image can be described in various ways. The names and the choices of the attributes might depend on the annotator’s perspective or linguistic preference (for example, one annotator could describe someone’s eye color as blue and another - as light grey). Thus, providing exhaustive and uniform annotations to each object is a large-scale task.
Nevertheless, some datasets explore the object attributes in depth. They include:
- COCO Attributes: Attributes for People, Animals, and Objects;
- Visual Genome: Visual Question Answering data in a multi-choice setting;
- VAW (Visual Attributes in the Wild): a large scale visual attributes dataset with explicitly labelled positive and negative attributes.
You can also check out the Multi-Label CLassification benchmarks of other datasets. We will provide some examples of the datasets and SOTA (state-of-the-art models benchmarked against these datasets) below.

Source
- PASCAL VOC 2007 dataset;
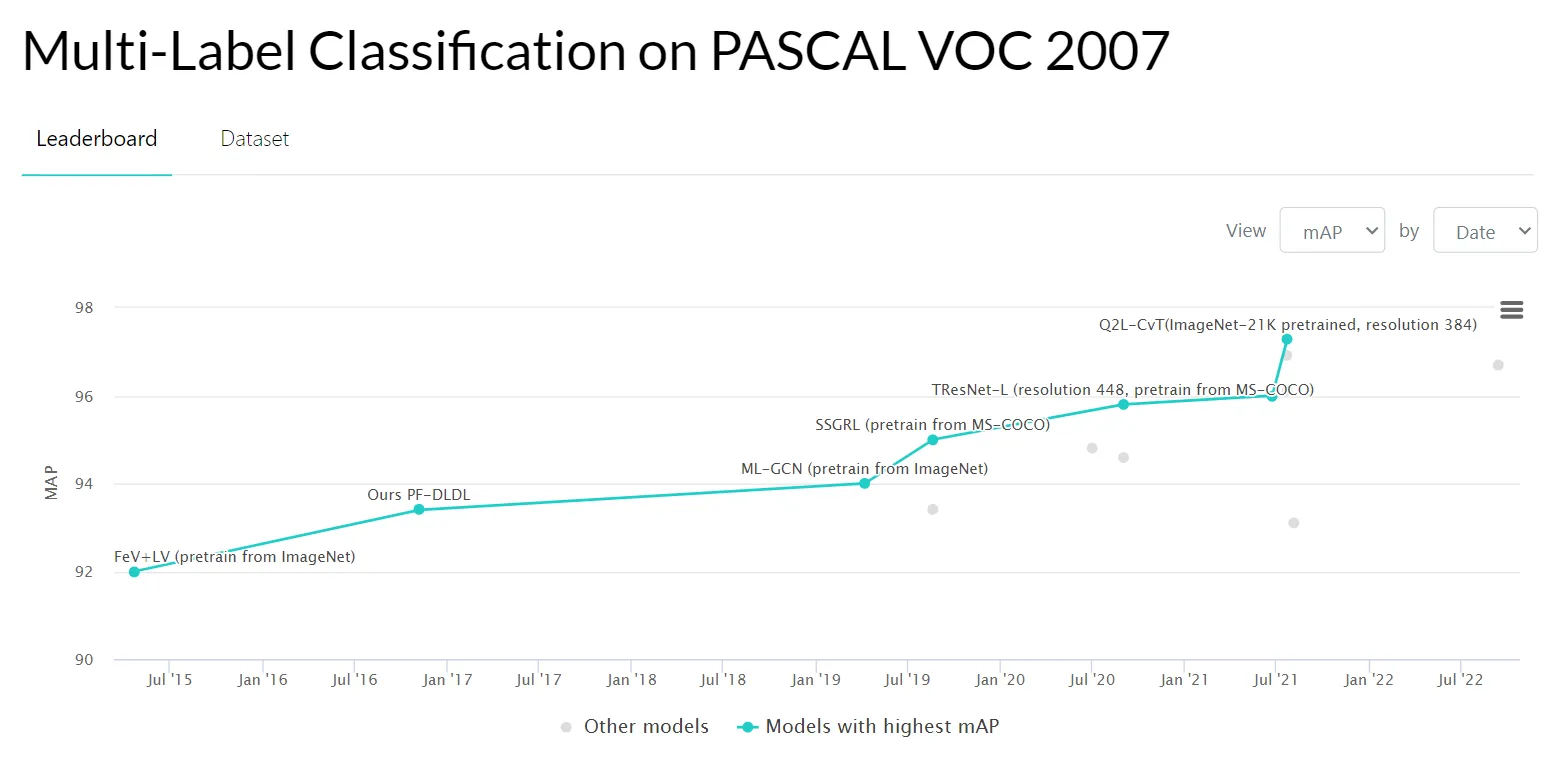
Source
- CheXpert: chest radiographs dataset;
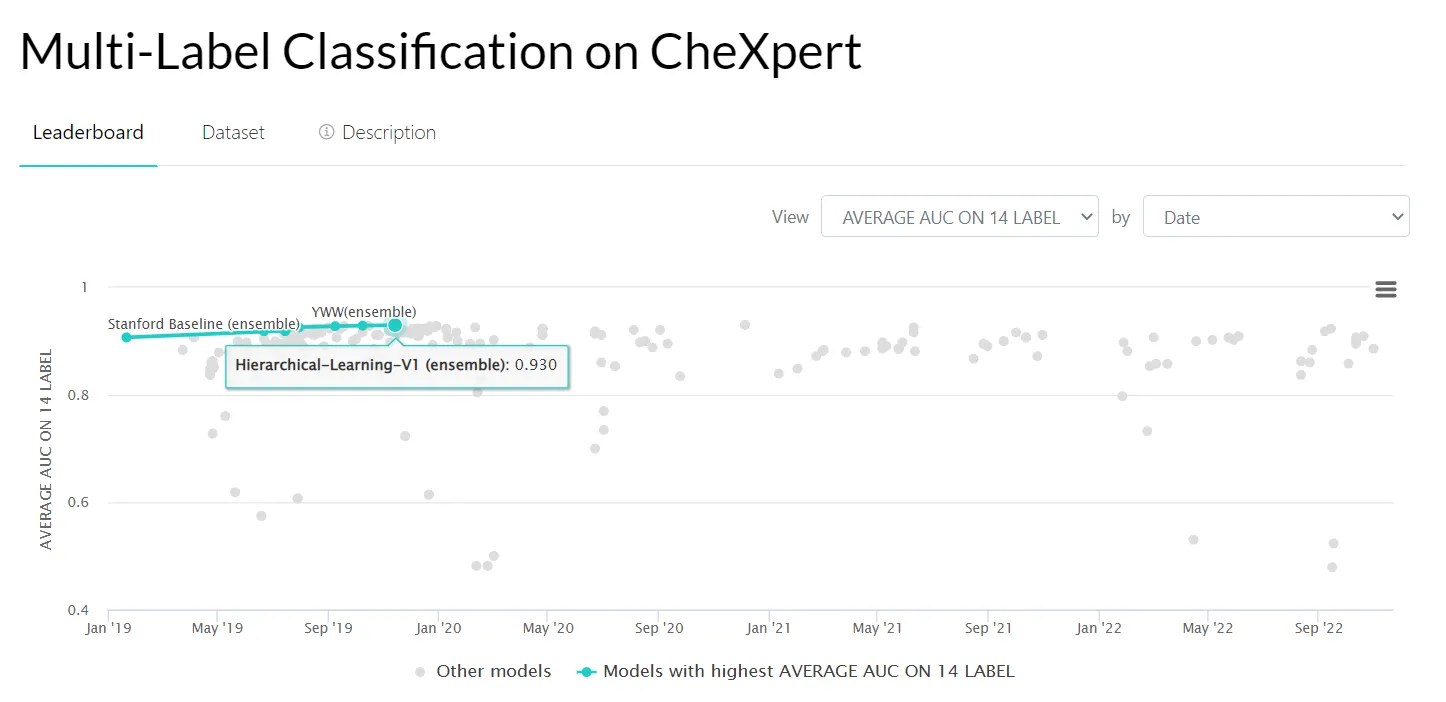
Source
- NUS-WIDE dataset;
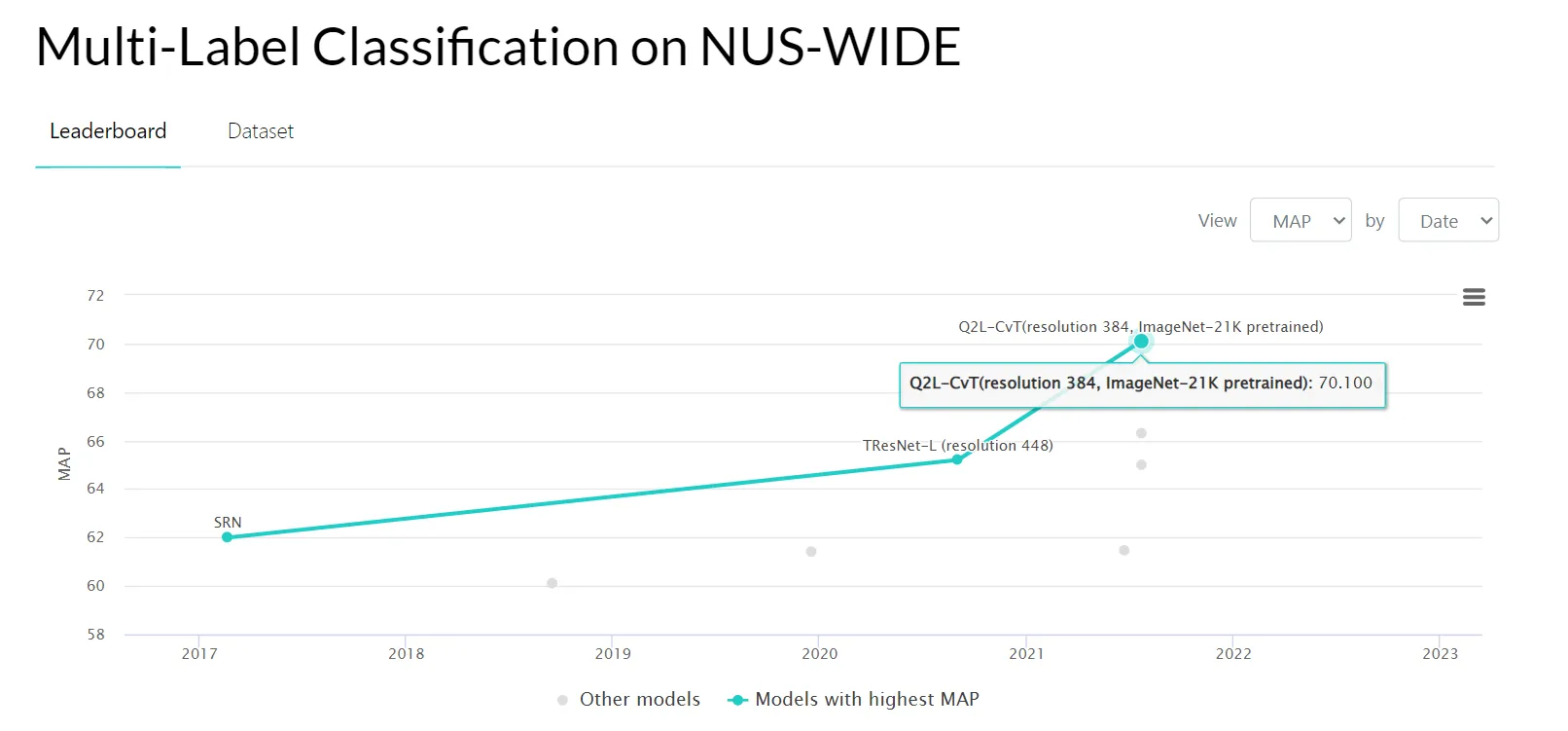
Source
- OpenImages-v6 dataset.
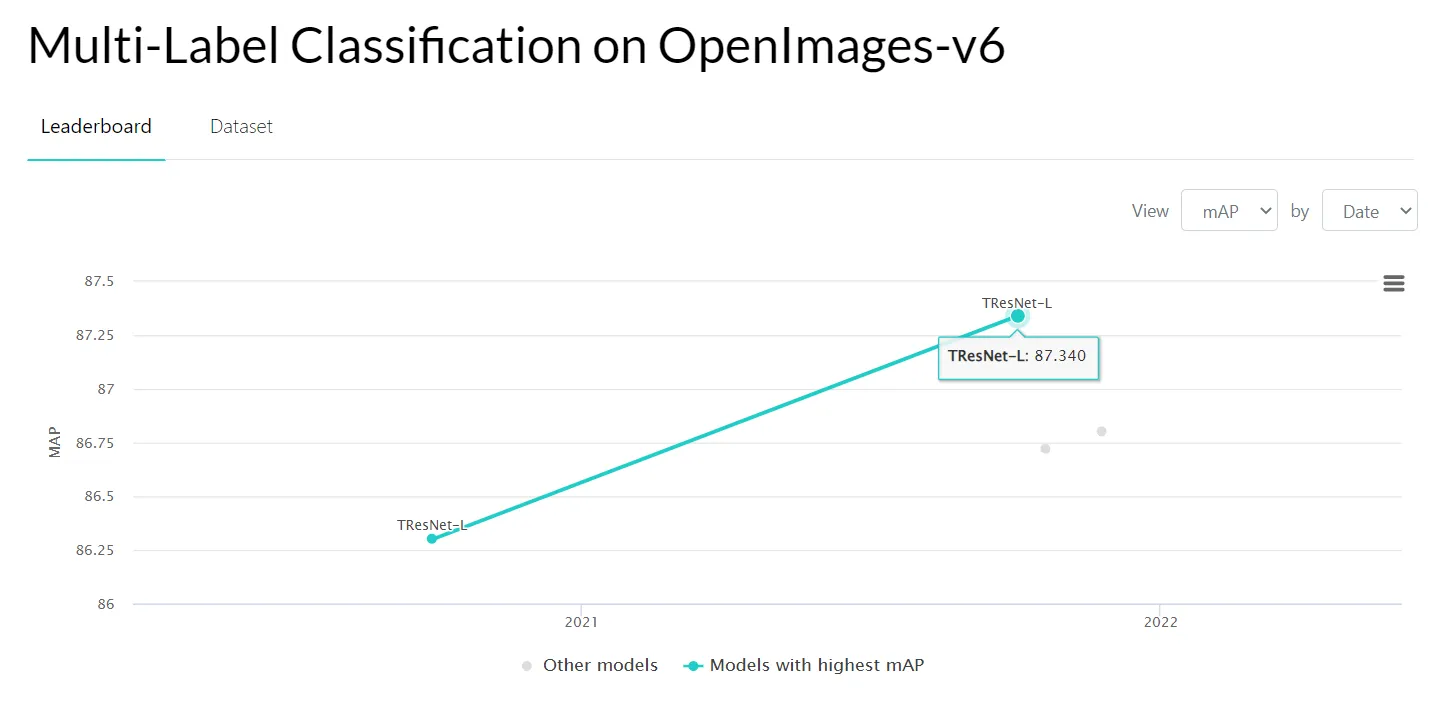
Source
How do we solve an Attribute Prediction task in CloudFactory?
To streamline the Attribute Prediction annotation experience, CloudFactory's internal data labeling tool supports an AI-powered Label Attribute assistant that predicts the image attributes automatically.
Regarding model development, CloudFactory's internal model-building tool supports many modern neural network architectures. For Attribute Prediction, these include:
- ResNet;
- EfficientNet;
- MobileNetV2;
- SWIN;
- ConvNeXt.
As for the Machine Learning metrics for the Attribute Prediction case, CloudFactory implements:
- Hamming Score;
- Loss;
- Precision;
- Recall.
As of today, these are the key technical options CloudFactory has for Attribute Prediction cases. If you want a more detailed overview, please check out the further resources or book some time with us to get deeper into CloudFactory with our help.