Semantic Segmentation
Computer Vision (CV) is a scientific field that researches software systems trained to extract information from visual data, analyze it, and draw conclusions based on the analysis. The area consists of so-called CV or vision AI tasks. Each task is unique and incorporates techniques and heuristics for acquiring, processing, analyzing, understanding the data, and extracting various details from it. One of these tasks is Semantic Segmentation. On this page, we will:
- Understand the basics of the Image Segmentation field in Machine Learning;
- Cover in-depth the Semantic Segmentation vision AI task;
- See how Semantic Segmentation compares with Instance and Panoptic Segmentation;
- Research the real-life applications of Semantic Segmentation;
- Cover some popular Semantic Segmentation datasets and SOTA results on them;
- See features that CloudFactory offers for streamlining a Semantic Segmentation task.
Let’s jump in.
What is Image Segmentation in Machine Learning?
It is essential to start with a bigger picture. The logical question is, what is Image Segmentation in Machine Learning?
Well, Segmentation is a well-known term in business and marketing. In short, it defines the process of splitting customers (or a whole market) into separate groups based on specific patterns in their behavior. Fortunately, such a definition is close to what we refer to when saying Image Segmentation in ML.
Image Segmentation in Machine Learning is a part of the vision AI field that incorporates different methods of dividing visual data (for example, an image) into segments featuring specific, similar, and significant information of the same class label.

Source
As of today, corporate Data Science regularly solves Image Segmentation challenges in various spheres. In CloudFactory, we see that the demand for high-quality Segmentation solutions has rapidly grown over the past couple of years. It also applies to Data Scientists who specialize in the Image Segmentation field. As a result, the industry is developing and growing, bringing new SOTAs, solution techniques, and challenges.
Nowadays, researchers say that the Image Segmentation field consists of three vision AI tasks. These are:
- Semantic Segmentation;
- Instance Segmentation;
- Panoptic Segmentation.
Let’s take a closer look at the Semantic Segmentation vision AI task.
What is Semantic Segmentation in Machine Learning?
Moving from the bigger picture to the details, let’s see what Semantic Segmentation is.
Semantic Segmentation is a Computer Vision task that focuses on classifying every pixel in an image to create a pixel-perfect segmentation map for a specific image. Here is a simple example of how such a map might look like:
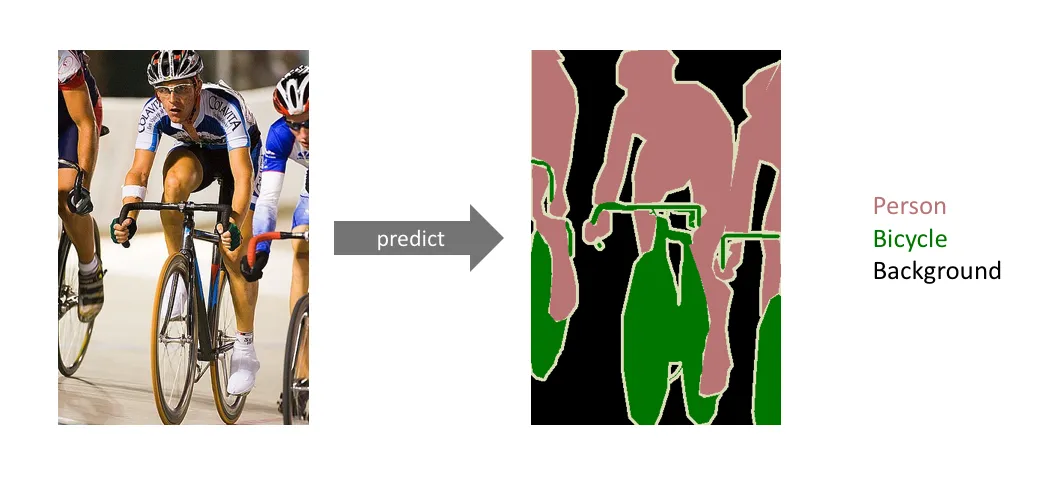
Source
The data annotation process for a Semantic Segmentation task is as follows:
You predefine some semantic target classes (for example, ‘person’, ‘bicycle’, and ‘background’ for an image above). Please note that for any Sematic Segmentation task, there is a default ‘background’ class that is used to mark all the space that does not correspond to any other class;
You assign each pixel on a picture to one of these classes.
To summarize, Semantic Segmentation receives an image and some semantic target classes as input. As an output, you get a pixel-perfect segmentation map of the whole picture, with each pixel assigned to a specific class.
Instance Segmentation Vs. Semantic Segmentation
Although Instance and Semantic Segmentation live in the same Image Segmentation field and share some similarities, they are still different vision AI tasks. You must remember it when identifying which task you aim to solve.
Semantic Segmentation classifies every pixel on an image, so all instances of the same category share the same class label. As a result, you get a segmentation map.

Source
On the other hand, Instance Segmentation ensures that all the objects of the same class are viewed as distinct instances. So, from an IS model, you get a bounding box and a segmentation mask for each object.

Source
Please consider the following question if you are unsure whether you should use Instance or Semantic Segmentation as your vision AI task. Do you want your model to be able to count distinct objects? If so, label data for an Instance Segmentation task. It is generally easy to use labels created for Instance Segmentation to solve a Semantic Segmentation task. However, the other way around is tricky. Please think carefully before rushing into the annotation process.
Panoptic Segmentation Vs. Semantic Segmentation
Although Panoptic and Semantic Segmentation live in the same Image Segmentation field and share many similarities, they are still different vision AI tasks. You must remember it when identifying which task you aim to solve.
Semantic Segmentation classifies every pixel on an image, so all instances of the same category share the same class label. As a result, you get a segmentation map.
Source
On the other hand, Panoptic Segmentation is a combination of Semantic and Instance Segmentation. In other words, with Panoptic Segmentation, you can obtain information such as the number of objects for every target class (countable objects), bounding boxes, segmentation masks, and a segmentation map of the whole image. These come from Instance Segmentation. However, you also get a segmentation map from Semantic Segmentation and know a target class for each pixel. So, Panoptic Segmentation provides a way more holistic understanding of a scene.

Source
Instance Segmentation Vs. Panoptic Segmentation Vs. Semantic Segmentation
Instance Segmentation | Find every distinct object of target classes | An image and some instance target classes | A bounding box and a segmentation mask for each instance of target classes |
Semantic Segmentation | Classify every pixel on an image | An image and some semantic target classes | Pixel-perfect segmentation map of the whole image |
Panoptic Segmentation | Combine Instance and Semantic Segmentation | An image and some instance and semantic target classes | Pixel-perfect segmentation map of the whole image and A bounding box and a segmentation mask for each instance of target classes |
Semantic Segmentation real-life applications
Nowadays, Image Segmentation is widely used across various industries. However, the question that comes to mind is whether Semantic Segmentation is the right vision AI task to solve in your particular case. As shown above, both Instance and Panoptic Segmentation might give you more detailed and valuable information in some scenarios. From our experience, Semantic Segmentation is often treated as a sub-task but not the primary one.
Still, Semantic Segmentation has many real-life applications, such as:
Autonomous driving systems (for example, segmentation of visual input data from the camera - classification of a pedestrian on the road, a vehicle, signs, etc.);
Source
Medical data processing (for example, segmentation of MRI images searching for tissues, tumors, anomalies, and their characteristics such as area, dynamics, etc.);
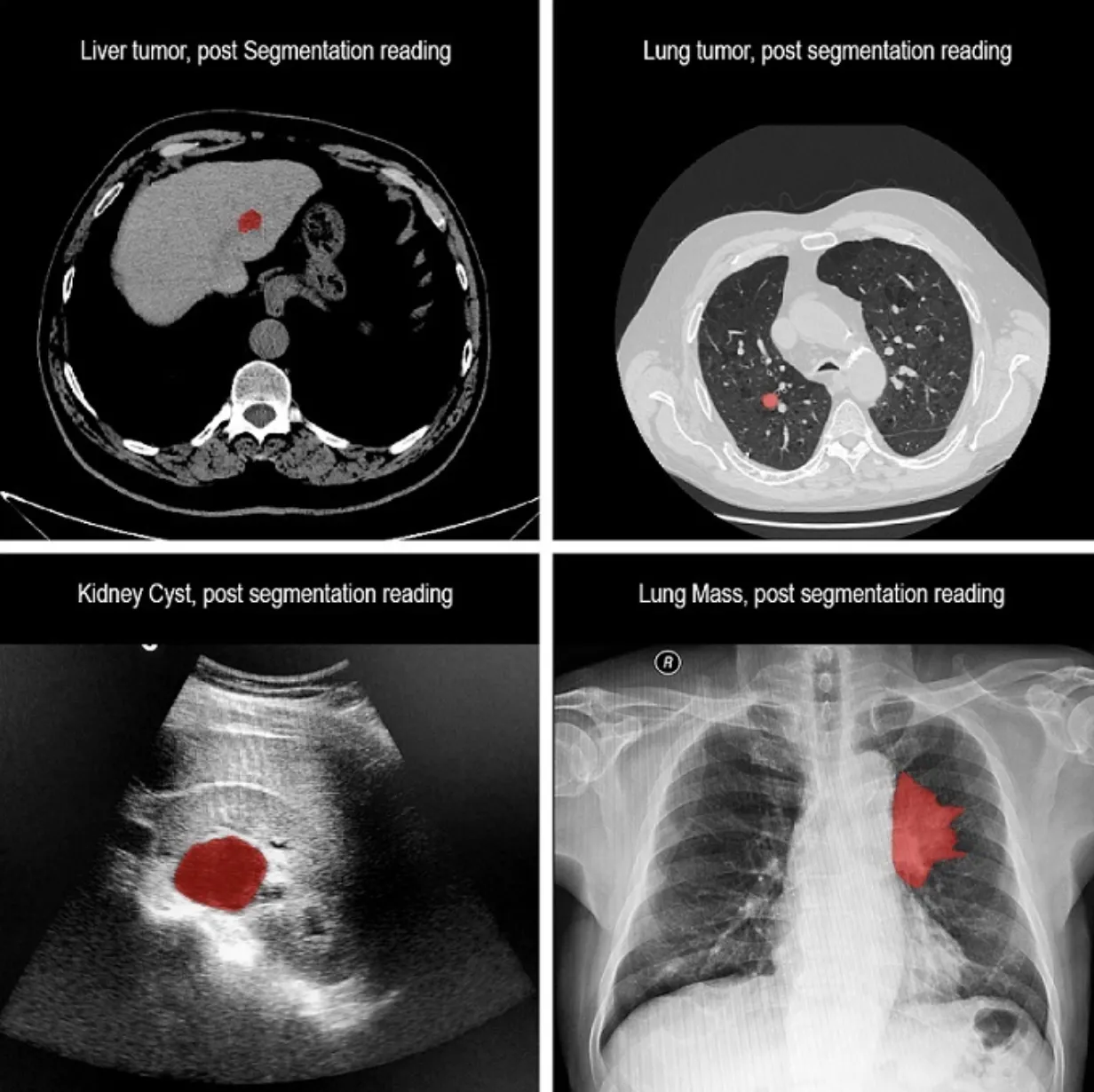
Source
Aerial, satellite, and UAV image processing (for example, segmentation of a landscape);

Source
Scene processing (for example, dividing objects in the scene into segments for more accessible further work on them);
And many other use cases.
Semantic Segmentation datasets
Speaking about Semantic Segmentation datasets and SOTA solutions, it is worth mentioning that many Image Segmentation datasets have Semantic Segmentation annotations within their labels. However, Semantic Segmentation might not be the primary focus of a dataset. This means that the annotations in such datasets might not be 100% accurate, leading to a need to run a quality control process before diving into solution design.
Still, there are trustworthy benchmark datasets regularly used to evaluate recent Semantic Segmentation model architectures and approaches. These are:
CamVid (Cambridge-driving Labeled Video Database);
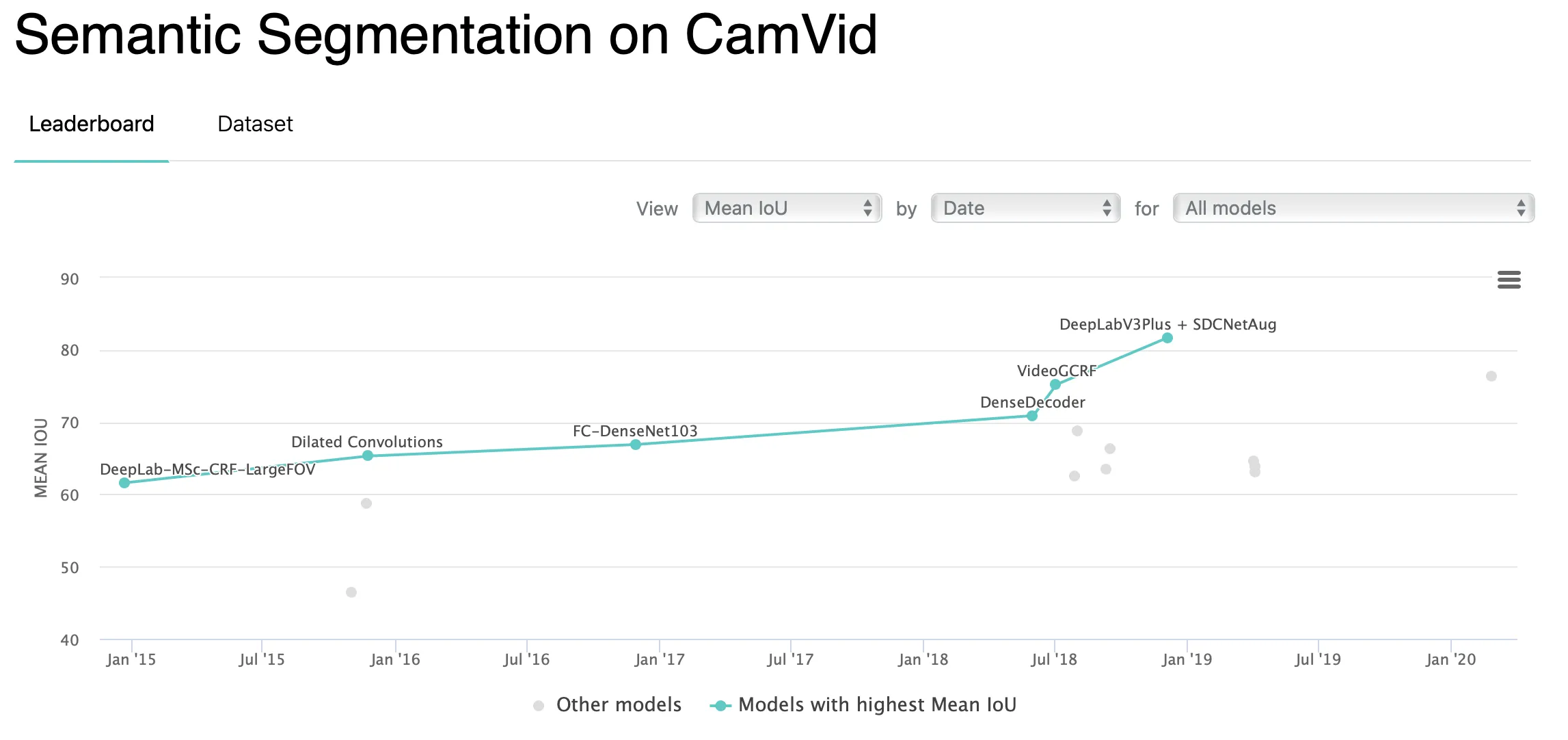
Source
COCO;
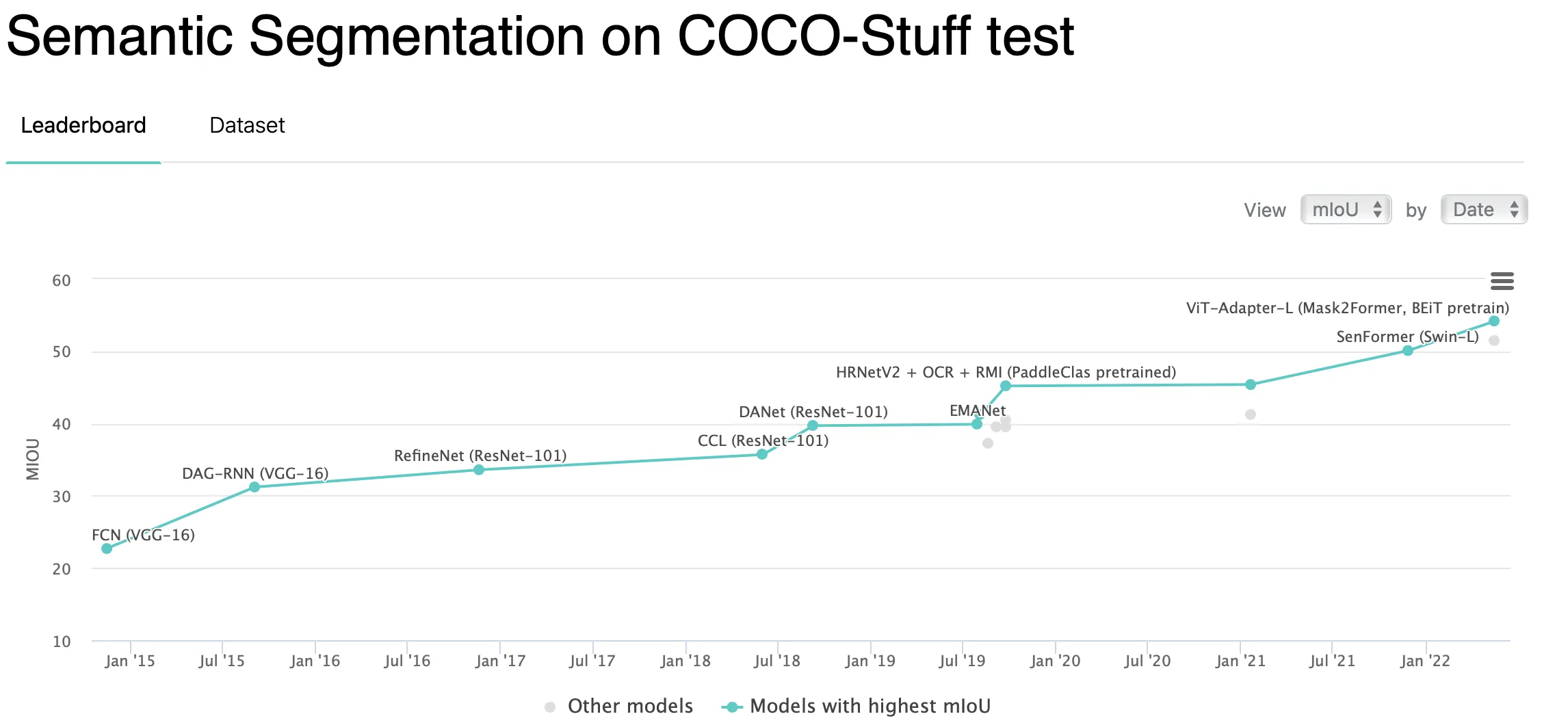
Source
MSeg (A Composite Dataset for Multi-domain Semantic Segmentation);
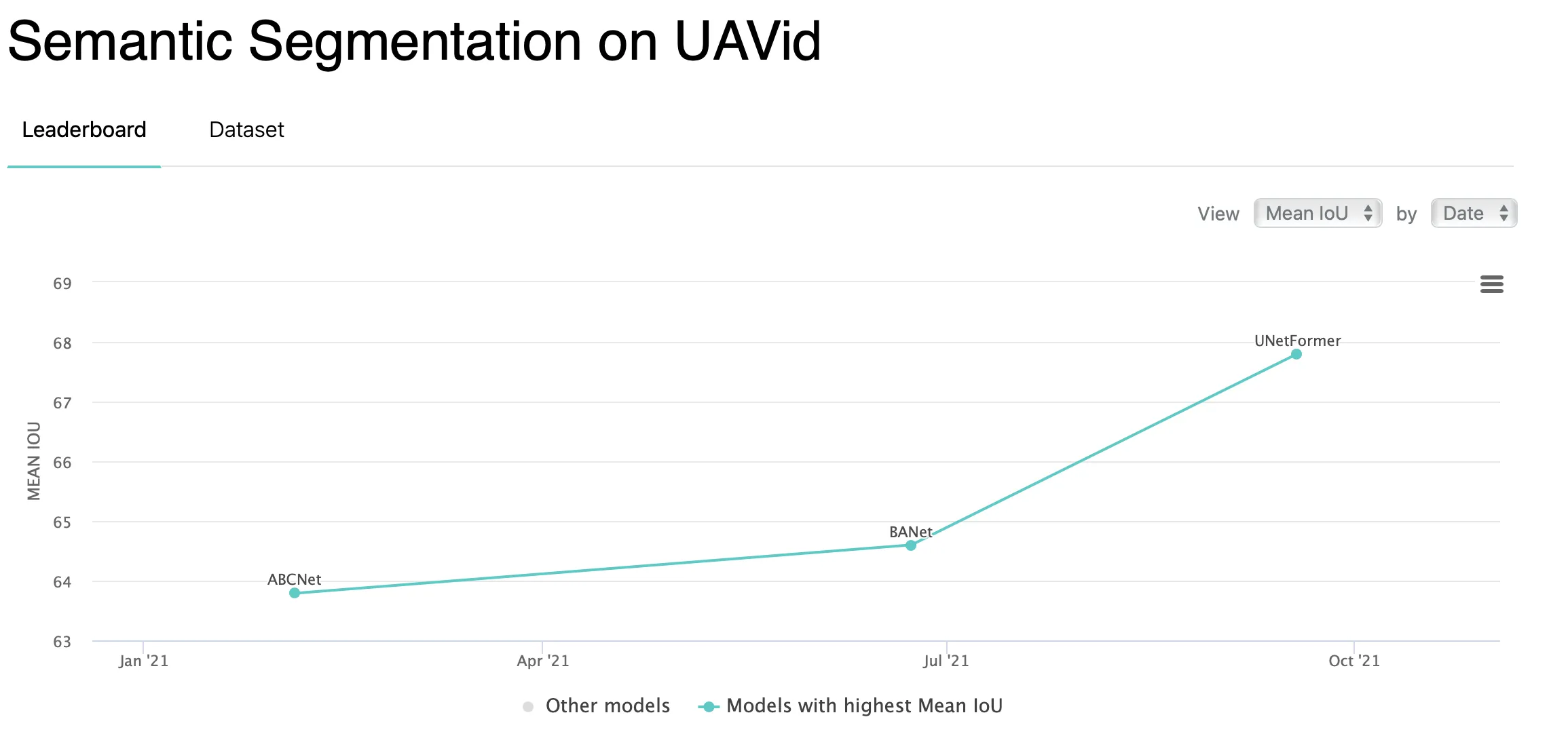
Source
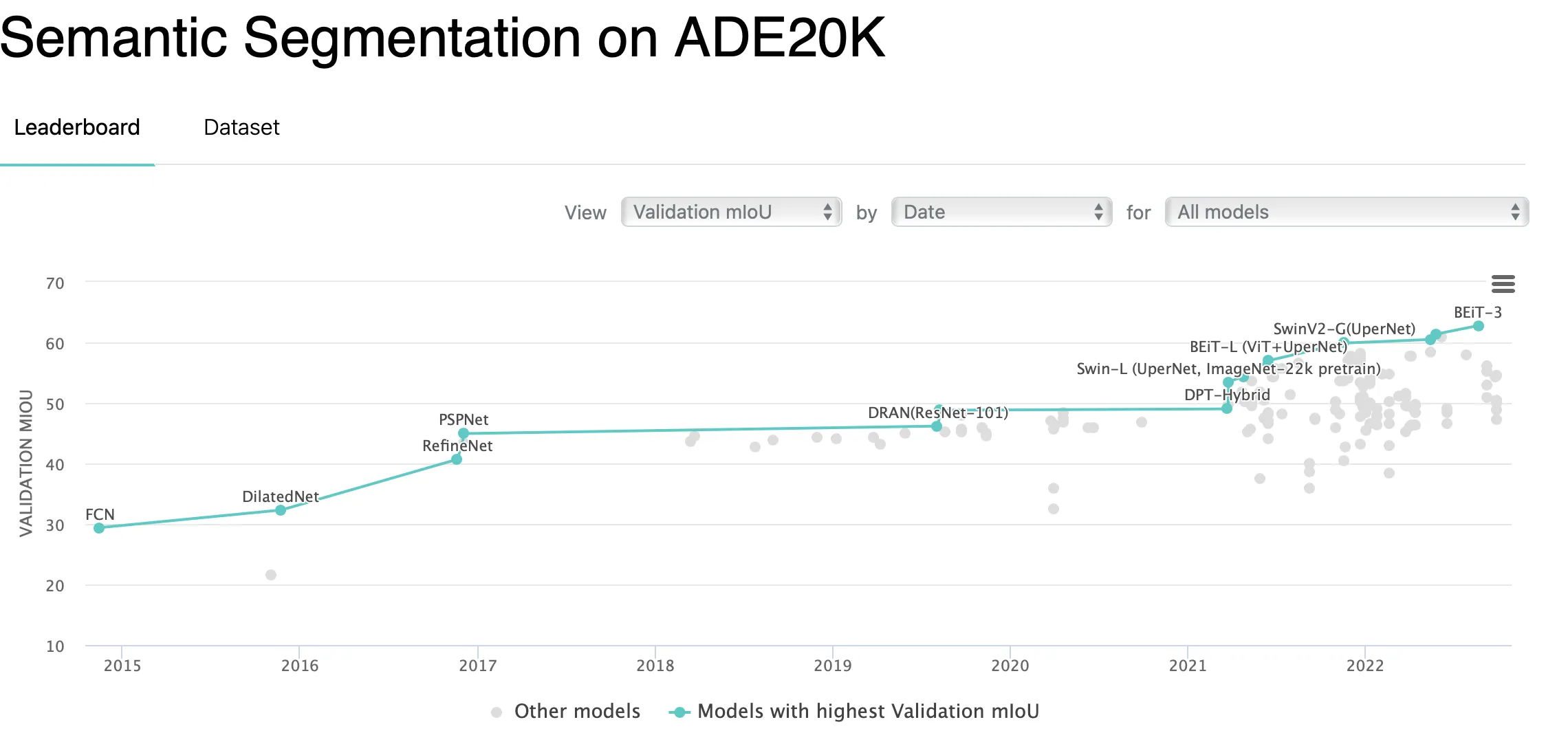
Source
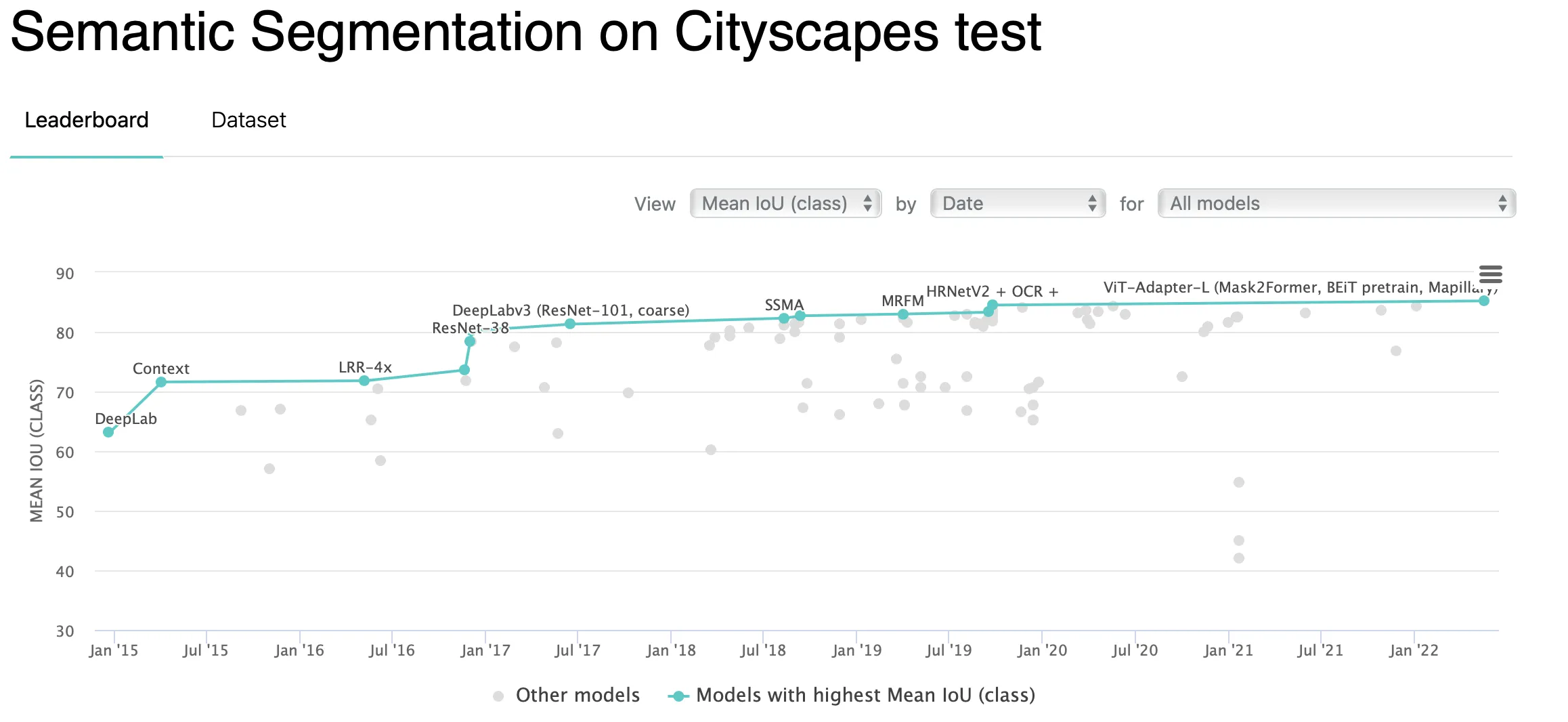
Source
How do we solve a Semantic Segmentation task in CloudFactory?
Throughout years in the industry, CloudFactory's IT team has developed many internal instruments that our cloudworkers and Data Scientists use when working on client cases.
Let’s go through the available options step-by-step. To streamline the Semantic Segmentation annotation experience, CloudFactory's internal data labeling tool supports:
- Manual annotation tools such as Polygon and Brush. Also, there is an option to convert polygon to mask and vice versa in a single click;
- Semi-automated annotation tools such as ATOM powered by SAM and Box to instance;
- AI-powered Semantic Segmentation assistant.
Regarding model development, CloudFactory's internal model-building tool supports many modern neural network architectures. For Semantic Segmentation, these include:
As a backbone for these architectures, CloudFactory offers:
- ResNet;
- EfficientNet;
- MobileNetV2;
- SWIN;
- ConvNeXt.
As a Machine Learning metric for the Semantic Segmentation case, CloudFactory implements mean Intersection over Union.
As of today, these are the key technical options CloudFactory has for Semantic Segmentation cases. If you want a more detailed overview, please check out the further resources or book some time with us to get deeper into CloudFactory with our help.