StepLR
If you have ever worked on a Computer Vision project, you might know that using a learning rate scheduler might significantly increase your model training performance. On this page, we will:
- Сover the Step Learning Rate (StepLR) scheduler;
- Check out its parameters;
- See a potential effect from StepLR on a learning curve;
- And check out how to work with StepLR using Python and the PyTorch framework.
Let’s jump in.
StepLR explained
StepLR is a scheduling technique that decays the learning rate by gamma every N epochs (or every N evaluation periods, if iteration training is used).
Parameters
- Step Size - the decay of the learning rate happens every N epochs. This "N" is the step size.
- Gamma - a multiplicative factor by which the learning rate is decayed. For instance, if the learning rate is 1000 and gamma is 0.5, the new learning rate will be 1000 x 0.5 = 500.
StepLR visualized
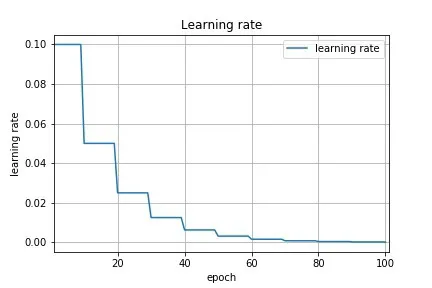
Source
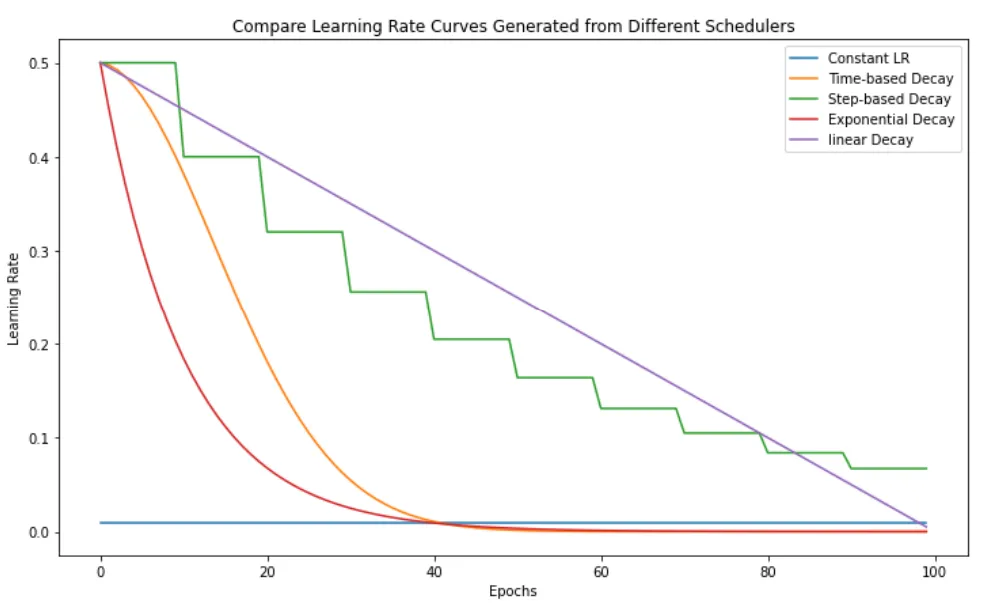
Source