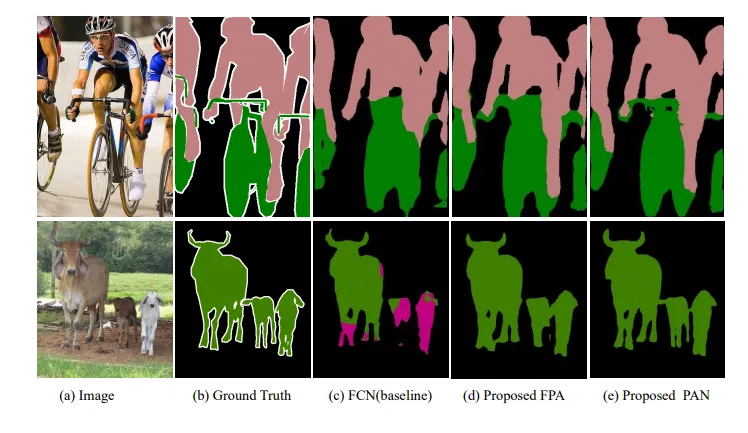
PAN
Pyramid Attention Network was proposed for semantic segmentation in order to better handle the cases of the images with objects of various sizes by extracting pixel-level details and to preserve the segmentation in the original resolution.
Source
Source
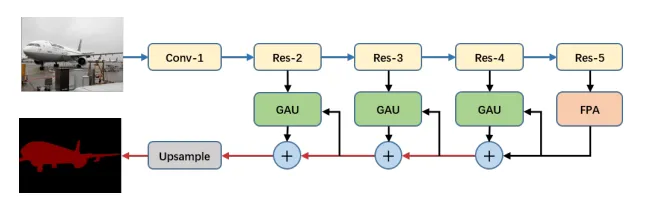
Basic Layout
The architecture of PAN is given above. We can see that it makes use of ResNet architecture for the encoder block. The encoder architecture gives us a high-level feature map. This feature map is fed into FPA, Feature Pyramid Attention.
Feature Pyramid Attention
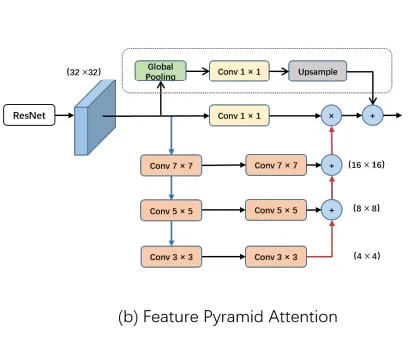
The pyramid attention module fuses features from under three different pyramid scales. Here they use three convolutions (7X7, 5X5, 3X3) to extract the context. We can see that the original feature is multiplied by the pyramid attention features after passing through a 1X1 convolution. Benefiting from spatial pyramid structure, the Feature Pyramid Attention module can fuse information from different scale contexts and produce better pixel-level attention for high-level feature maps.
After producing a segmented feature map, we need the original resolution of the image. Architectures like DeepLabv3+ or PSPnet make use of naïve bilinear upsampling. PAN uses GAU, Global Attention Upsample as its decoder block.
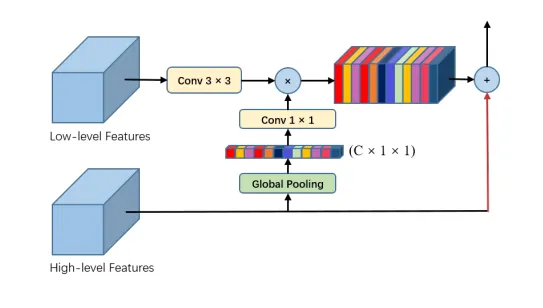
Global Attention Upsample
PAN uses a decoder technique called Global Attention Upsampling that makes use of the attention technique and global pooling to decode the feature map to the original resolution.
Source
Parameters
Encoder Network
It is the network that is used to extract the high-level feature map for the segmentation. In the first image, we can see that ResNet has been used.
Weight
It is the weight initialization for the encoder network.
Weight
It defines the weight for the entire Pyramid Architecture Network. Here, the weights are assigned randomly.
Decoder Channels
In the above Global Attention Upsampling, we can see a 3X3 convolution being used for reducing the number of filters in the low-level features. The number of filters used in 3X3 convolution is the decoder channels.