FBNetV3IS
FBNetV3 makes up a family of state-of-art compact neural networks that are generated through Network Architecture Recipe Search, NARS. NARS is an advanced version of Network Architecture Search that searches for both the architecture and the training recipes. FBNetV3 has been shown to improve the mAP (mean Average Precision).
General FBnetV3
The main idea behind FBNetV3 architecture is to search for an architecture using technologies such as NARs and evolutionary search. With search space containing all the distinctive components of an Instance Segmentor such as Mask Head, FBnetV3 is able to yield an Instance Segmentor.
This Instance Segmentor is referred to as FBNetV3IS.
Parameters
Backbone Network
Many image segmentation or object detection tasks are using feature extraction and use of regional proposals as it was proven to be more cost-effective. Therefore, FBNetV3 has a similar backbone network at the beginning to extract such features.
Pooler Resolution (Mask)
It is the size to pool proposals before feeding them to the mask predictor, in the model playground the default value is set as 14.
Pooler Resolution (Box)
It is the size to pool proposals before feeding them to the mask predictor, in the model playground the default value is set as 6.
Weights
Before the training process, the weights in the neural network have to be initialized to a certain value. The users will initialize the weights to FBNetV3a-DSMask-C4 COCO.
IoU Threshold
The IoU threshold is used to decide whether the bounding box contains a background or an object.
Everything above the value of the upper bound will be classified as objects and everything lower than the lower bound will be classified as background. The values in between the lower and the upper bound are ignored.
Stages to Freeze
Freezing the stages is useful when you have a relatively small amount of data and the data doesn't differ much from the ones that created the initial weights. For example, weights can be initialized with FBNetV3a-DSMask-C4 COCO while using FBNetV3 for instance segmentation in Hasty. If your data is similar to COCO and has a relatively small amount of data, then it might be a good idea to freeze some of the initial k layers and only train the remaining (n-k) layers. This prevents the overfitting of the model and also reduces the time to train the model.
Normalization method
Normalization techniques help to decrease the overall training time of the model. It makes the contribution of the features uniform by normalizing the weights. This also helps to avoid the weights from exploding and hence makes the optimization faster.
There are three available normalization methods in the Model Playground:
- SyncBN;
- NaiveSyncBN;
- GN (Group Batch normalization).
SyncBN
In this normalization technique, where the weights are scaled and shifted by the variance and the mean. Mathematically, it is given as:
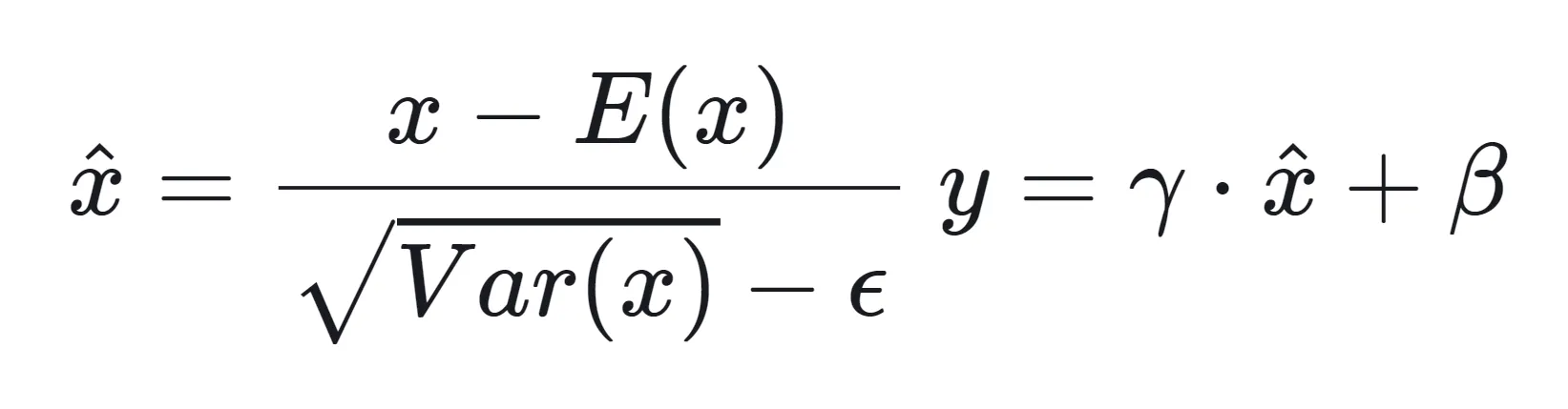
The mean and standard deviation are calculated per dimension overall mini-batches of the same process groups. Later again, the scaling and shifting happen with the other two constants: gamma and beta. These are hyperparameters and are usually learnable through the network.
NaiveSyncBN
In this normalization technique, the weights are assigned equally to all the images regardless of their dimension. With this, we reduce the need to accurately compute the mean and variance for each of the batches. A little difference has been observed between such simplified calculation and accurate mean and variance calculation.
GN (Group Batch normalization)
Group Batch normalization, abbreviated as GN, is another normalization technique that normalizes a group of parameters. If the input dimension is 50, then the GN normalization can group those 50 parameters in a group of 5, and normalize each group with its own mean and variance.
Pre-NMS number of proposals
It is the maximum number of proposals to be considered before the non-maximal suppression. The proposals are sorted descending after confidence and only the ones with the highest confidence are chosen.
Post-NMS number of proposals
It is the maximum number of proposals to be considered after the non-maximal suppression. The probability of detecting more objects is high if this number is high but the computation cost is also increased since more regional proposals have to be processed.