SGD
Deep learning optimizer literature starts with Gradient Descent and the Stochastic Gradient Descent (SGD) is one very widely used version of it. The gradients are not calculated for the loss functions over all data points but over a randomly selected sub-sample. This is why it is also called mini-batch gradient descent sometimes.
Most relevant hyper-parameters of SGD:
Intuition
Gradient Descent
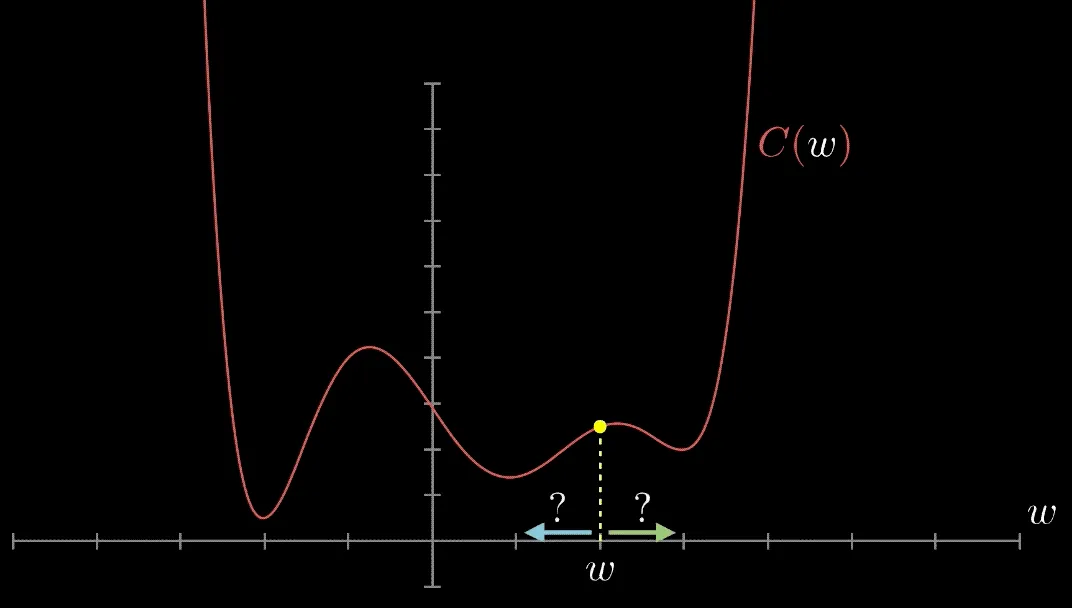
The goal of each solver is to find the loss function's minimum. However, this cannot be done by just setting the derivative to 0 (as you learned to do in calculus I) because there is no closed-form solution. This is because the loss landscape of neural networks is highly non-convex and riddled with saddle points.
Have you met Gradient Descent? Gradient Descent is an algorithm that finds local minima. It calculates the gradient of a given point on a loss function. If the gradient is negative, it updates the weights moving to a point in the direction of the gradient; if it's positive to a point in the opposite direction. This is repeated until the algorithm converges. Then, we have found a local minimum—or are at least are very close to it.
In the vanilla form, the only parameter to know is the base learning rate.
Stochastic Gradient Descent (SGD)
SGD is a more computationally efficient form of Gradient Descent.
SGD only estimates the gradient for the loss from a small sub sample of data point only, enabling it to run much faster through the iterations. Theoretically speaking, the loss function is not as well minimized as with BGD. However, in practice, the close approximation that you get in SGD for the parameter values can be close enough in many cases. Also, the stochasticity is a form of regularization, so the networks usually generalize better.