RetinaNet
General Information
RetinaNet was first introduced to discuss Focal Loss and its use in one-stage Object Detectors. It had been observed that the accuracy of the one-stage detector always trailed behind the two-stage detectors. The paper that introduced RetinaNet has shown that the foreground and background class imbalance during the training of dense detectors was the central cause for the one-stage detectors to lag behind the two-stage detectors. Focal Loss was introduced to mitigate this problem.
Source
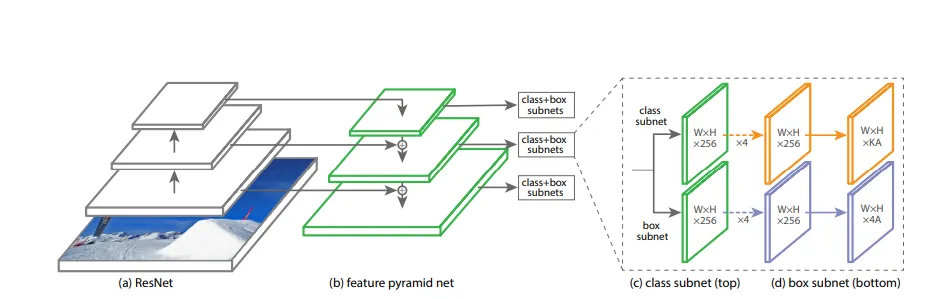
RetinaNet uses ResNet and feature pyramid net (FPN) as a backbone for feature extraction and uses two subnets for classification and bounding box regression. We can visualize this in the given image.
RetinaNet in Model Playground: Parameters
Backbone Network
This network is required to extract the feature map from the original input image. With the help of ResNet and FPN, feature maps of different resolutions are obtainable.
Depth of ResNet model
This defines the depth of the ResNet model that is used to extract the features.
Weight
It is the weight by which the model is initialized. Here, the weight is initialized with the weights of ResNet 50 trained on the COCO dataset if the depth of the ResNet model is chosen to be 50. Otherwise, the weights are assigned randomly.
IoU Thresholds
Like any other object detection task, the IoU threshold is used to differentiate the anchors which contain foreground or background objects. If the IoU of the anchor is less than the lower limit, then the object in the anchor is the background. If the IoU of the anchor is greater than the upper limit, then the object within will be classified as a foreground image.
Number of Convolutions
This parameter defines the number of convolutional layers in the box and class prediction heads. This does not include the final prediction layer. In the example image above, since there are 2 convolutional layers in the class and box subnets before the final layer, the "number of convolutions" parameter will be set to 2.
NMS threshold for Test
The object detection algorithms produce many bounding boxes for the same object to be detected. Ideally, we would want a single bounding box for each object in the image. Hence, at first, we select the bounding box with the highest confidence score. Then, we calculate the IoU of all the remaining bounding boxes with the box with the highest score. If the IoU is greater than the threshold we eliminate the bounding box.
Top K candidates
From the image above, we can see we obtain feature maps of different resolutions from the feature pyramid. From each of the feature pyramids, the top K candidates with the highest confidence score are selected and merged. Later NMS is applied to these combined boxes.
Stages to Freeze
Freezing the stages in a Neural Network is a technique that was introduced to reduce computation. After the stages have been frozen, the optimizer doesn't have to back-propagate to it. Freezing many stages will help the computation be faster but aggressive freezing can degrade the model output and can result in sub-optimal predictions.