Confusion Matrix
If you have ever tried solving a Classification task using a Machine Learning (ML) algorithm, you might have heard of such a way to evaluate the model’s performance as a Confusion matrix. On this page, we will:
- Сover the logic behind the metric (both for the binary and multiclass cases);
- Find out how to interpret the Confusion matrix;
- Calculate the matrix on two simple examples;
- And check out how to work with the Confusion matrix using Python.
Let’s jump in.
What is Confusion matrix?
A Сonfusion matrix is a table used to evaluate the accuracy of the ML model’s performance on a Classification task. Technically speaking, the matrix itself is not really a Machine Learning metric. It is more of a heuristic used as a basis for various metrics. However, many ML Classification metrics are calculated on top of the Confusion matrix as it is an excellent indicator of the model’s performance.
In detail, the Confusion matrix is the basis for such metrics as:
- Accuracy;
- Precision;
- Recall;
- F-score;
- And mean Average Precision (mAP).
One of the substantial advantages of the Confusion matrix is its versatility. You can use the method both for the binary and multiclass Classification tasks. Let’s break these cases down one by one.
Confusion matrix example for Binary Classification
The Confusion matrix for the binary case looks as follows.

To calculate it, you need to compare the classifier’s predictions and the ground truth class labels. As you can see, the names of the rows and the columns in the table have the words 'Positive' and 'Negative' in them. These words indicate the classes (kind reminder, we are reviewing the binary case).
The Confusion matrix for the binary case derives four types of predictions. These are:
- True Positives (TP): if the predicted class for a sample is Positive and the ground truth class is also Positive, then the prediction is True Positive;
- False Positives (FP): if the predicted class for a sample is Positive, but the ground truth class is Negative, then the prediction is False Positive (in statistics, such a mistake is called the Type I Error);
- True Negatives (TN): if the predicted class for a sample is Negative and the ground truth class is also Negative, then the prediction is True Negative;
- False Negatives (FN): if the predicted class for a sample is Negative, but the ground truth class is Positive, then the prediction is False Negative (in statistics, such a mistake is called the Type II Error).

To calculate the matrix, you simply need to assign the number of the prediction/ground truth combinations to the table.
Confusion matrix example for Multiclass Classification
Strictly speaking, a Confusion matrix C is such that C (i, j) equals the number of observations known to be in group i and predicted to be in group j. So, the multiclass case simply expands the binary one. Let’s say we have three classes - 'Positive', ‘Negative', and 'Neutral'. In this case, the matrix will look as follows:
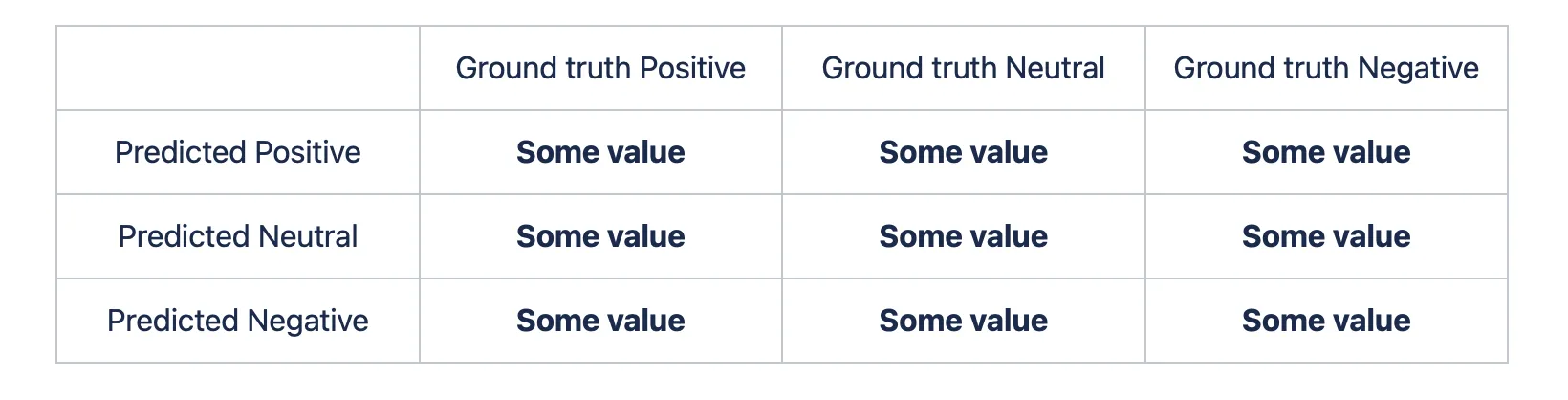
So, the only thing that changed was the addition of one more row and column. We would add two more rows and columns if we had four classes. It is as simple as that.
Also, as you can see, the multiclass case does not have a strict prediction/ground truth combinations terminology. Still, the matrix calculation process is the same - assign the number of the prediction/ground truth combinations to the table and be happy with yourself.
Interpreting Confusion matrix
The Confusion matrix is not straightforward to analyze and interpret (especially the multiclass one). It is pretty helpful if you want to check the direct tradeoff between the False Positives and False Negatives for binary Classification, but beyond that, it is rather useless.
Still, as mentioned above, you can calculate more interpretable metrics with the Confusion matrix results. Check out the metrics based on the Confusion matrix section to learn more.
Confusion matrix calculation example
Let’s check out a simple example.
Imagine solving a binary Classification task. For example, you are trying to determine whether a cat or a dog is on an image. You have a model and want to evaluate its performance using the Confusion matrix. You pass 15 pictures with a cat and 20 images with a dog to the model. From the given 15 cat images, the algorithm predicts 9 pictures as the dog ones, and from the 20 dog images - 6 pictures as the cat ones. It is time to build a Confusion matrix.
The workflow is straightforward. Let’s say that the cat images are a Positive class, whereas the dog pictures are a Negative one:
- Of the 15 cat images (P), 9 were predicted as the dog ones. So, only 15 - 9 = 6 predictions were correct. TP = 6;
- Of the 20 dog images (N), 6 were predicted as the cat ones. So, 20 - 6 = 14 predictions were correct. TN = 14;
- 9 pictures were predicted as the dog ones, but they actually have a cat on them. So, FN = 9;
- 6 images were predicted as the cat ones, but they actually have a dog on them. So, FP = 6.
Here is the matrix itself:

Ok, great. You decide to expand the task and add another class, for example, the bird one. You pass 15 pictures with a cat, 20 images with a dog, and 12 pictures with a bird to the model. The predictions are as follows:
- 15 cat images: 9 dog pictures, 3 bird ones, and 15 - 9 - 3 = 3 cat images;
- 20 dog images: 6 cat pictures, 4 bird ones, and 20 - 6 - 4 = 10 dog images;
- 12 bird images: 4 dog pictures, 2 cat ones, and 12 - 4 - 2 = 6 bird images.
Let’s build the matrix.
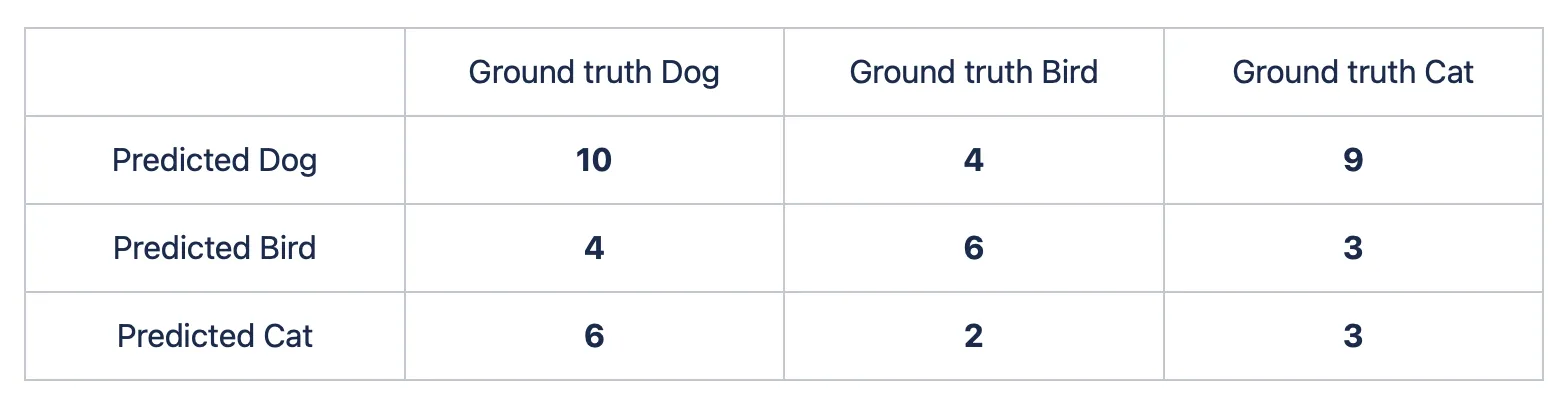
If you want to check whether your Confusion matrix is correct, simply summarize the values in each column. If everything is fine, you will get the initial number of class samples passed to the model. For example:
- Ground Truth Dog: 10 + 4 + 6 = 20 dog images were passed to the model;
- Ground Truth Bird: 4 + 6 + 2 = 12 bird images were passed to the model;
- Ground Truth Cat: 9 + 3 + 3 = 15 cat images were passed to the model.
Plotting Confusion matrix in Python
The Confusion matrix is widely used in the industry, so all the Machine and Deep Learning libraries have their own implementation of this measure. For this page, we prepared three code blocks featuring building Confusion matrix in Python. In detail, you can check out:
- Confusion matrix in Scikit-learn (Sklearn);
- Confusion matrix in PyTorch;
- Confusion matrix in TensorFlow.
Confusion matrix in Sklearn (Scikit-learn)
Scikit-learn is the most popular Python library for classical Machine Learning. From our experience, Sklearn is the tool you will likely use the most to build a Confusion matrix. Fortunately, you can do it in just a few lines of code.
Beyond the basic functionality, Sklearn has various Confusion matrix options implemented. You should definitely check them out to simplify your workflow.