ExponentialLR
If you have ever worked on a Computer Vision project, you might know that using a learning rate scheduler might significantly increase your model training performance. On this page, we will:
- Сover the Exponential Learning Rate (ExponentialLR) scheduler;
- Check out its parameters;
- See a potential effect from ExponentialLR on a learning curve;
- And check out how to work with ExponentialLR using Python and the PyTorch framework.
Let’s jump in.
ExponentialLR explained
The Exponential Learning Rate scheduling technique divides the learning rate every epoch (or every evaluation period in the case of iteration trainer) by the same factor called gamma. Thus, the learning rate will decrease abruptly during the first several epochs and slow down later, with most epochs running with lower values. The learning rate aspires to zero but never reaches it.

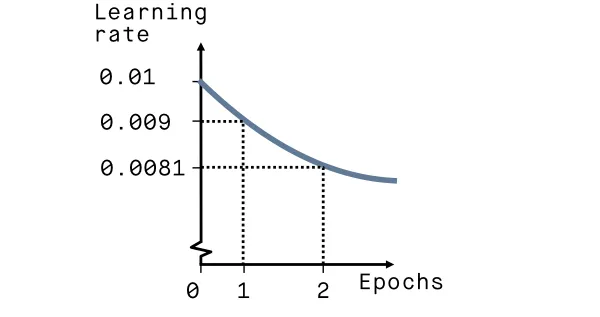
At the last epoch, the algorithm sets the learning rate as the initial Base Learning Rate.
Parameters
- Gamma - a multiplicative factor by which the learning rate is decayed every epoch. For instance, if the learning rate is 1000 and gamma is 0.5, the new learning rate will be 1000 x 0.5 = 500.
ExponentialLR visualized
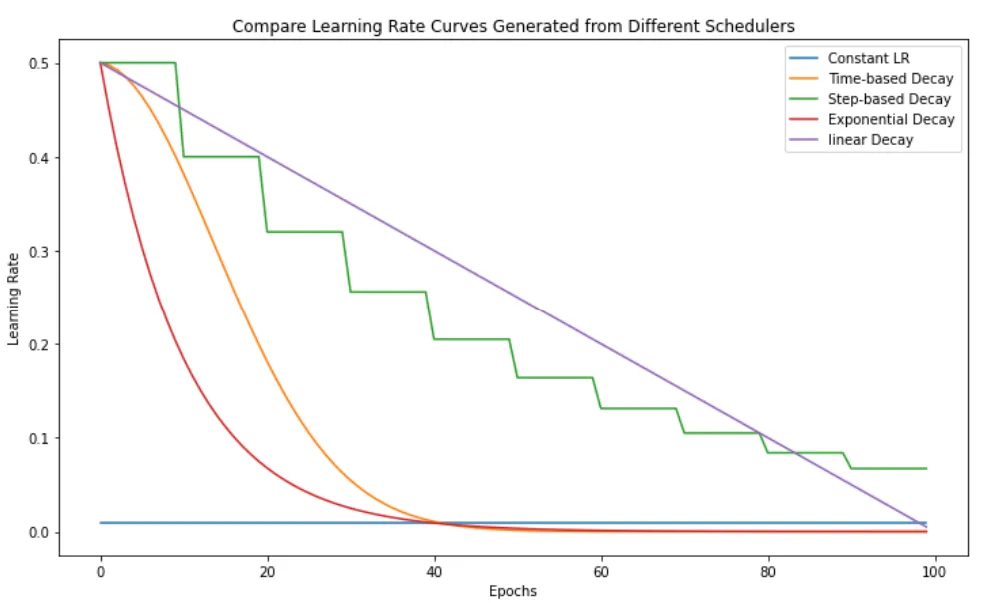
Source