The complete glossary of the modern Computer Vision tasks
Like in any other field, Computer Vision (CV) has a set of various tasks developers solve when building a Machine Learning (ML) solution. To define the term, a CV task determines what must be done for the solution to be considered successful. For example, you might need to classify an image, detect an object on some visual input, or segment each pixel on a picture.
The tasks might combine with one another, bring an unexpected point of view on a problem, or be unobvious in their formulations. Therefore, a general grasp of the field is essential as it gives you a well-rounded high-level understanding of potential views on problems and challenges you might face. Also, the ability to decompose a use case and match it with corresponding vision AI tasks is crucial when designing your solution.
Let’s jump in.
Primary Computer Vision tasks
The most common CV tasks can be split into 3 groups. Each group has a set of tasks that stick to a particular paradigm. For example, any Classification task means assigning a specific label to a certain object (this might be a whole image, an object on a picture, etc.). These groups and the corresponding particular tasks are:
Classification - assigning a specific label to a certain object;
Detection - detecting and classifying a particular object;
Segmentation - dividing an image into separate parts or sections;
You might have already heard about some, if not all, of the tasks listed above, as they are basic for the CV field. We will not go deep into them here as we have detailed guides for each. Please follow the links to learn more about the task you are interested in.
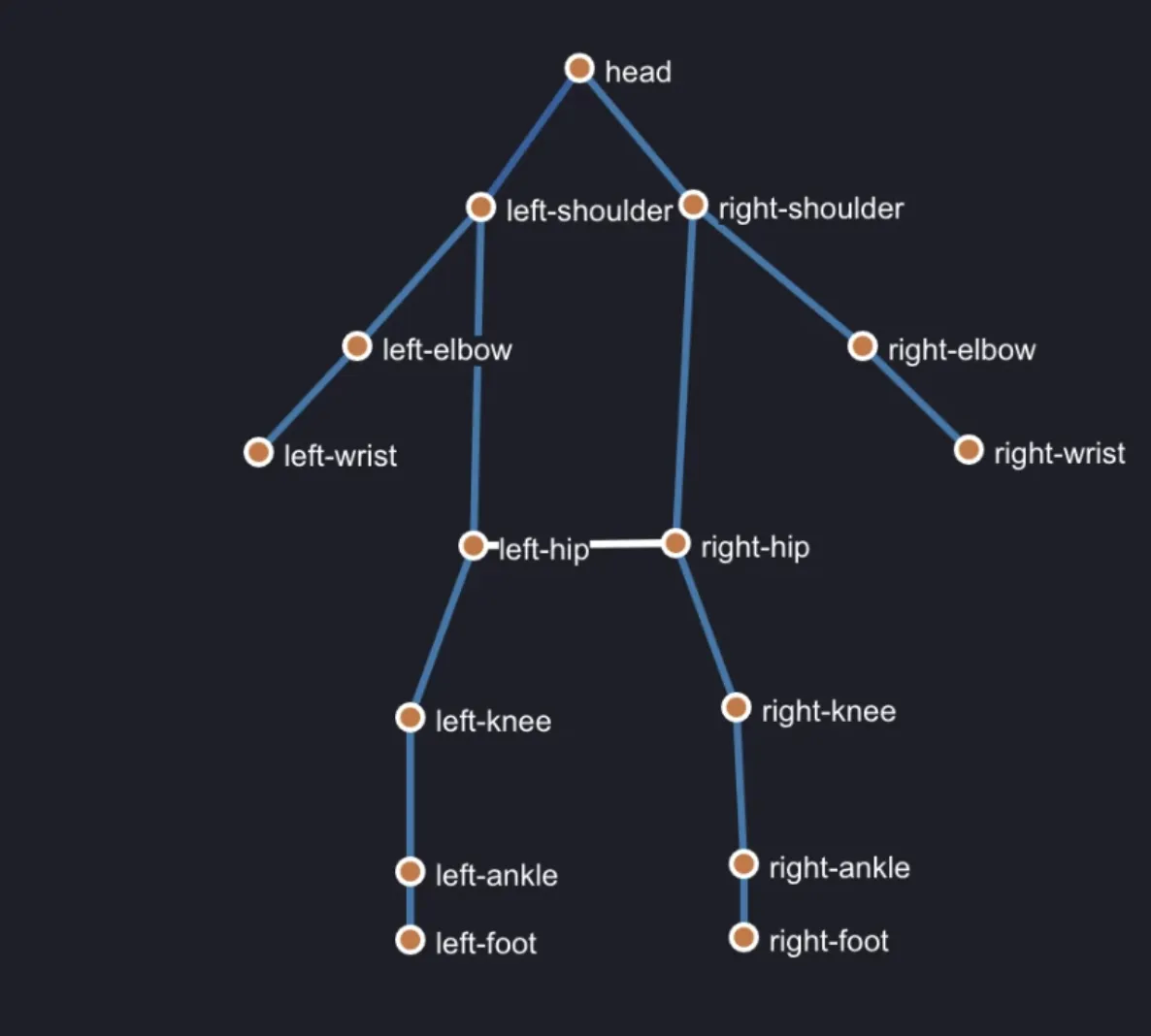
Pose Estimation
Pose Estimation is a vision AI task of approximating objects or human bodies' spatial position and orientation/pose from visual input. It involves estimating the position and orientation of predefined keypoints of the object or human body.
Source
For clarity, Pose Estimation can be viewed from 2D and 3D perspectives. However, working with 3D Pose Estimation is quite different because adding another dimension and going for 3D makes your task more complex, bringing more challenges to solve.

Source
Object Tracking
Object Tracking is a continuous CV task that aims to track a specific object or multiple objects over a sequence of frames, for example, over a videotape. The ultimate goal of any Object Tracking algorithm is to detect necessary objects and follow them as they move and undergo changes in appearance or pose.
Source
The definition is straightforward, but the task is multi-level, with complexities at each step. These might include:
Significant object appearance variations throughout the tape;
Occlusions;
Fast motion and motion blur;
Entering and leaving the frame for the same object;
etc.
Facial Recognition
Facial Recognition is a Computer Vision task that aims to identify or verify individuals based on their facial landmarks. The goal is utilized by extracting a person’s facial features and comparing them against a database of known faces.
Facial Recognition is widely used for identification and authentication purposes. The most common example of this task is Apple’s Face ID.

Source
Facial Landmarks usually include various points for:
Eyes;
Eyebrows;
Nose;
Lips;
And the face shape.

Source
Image Generation (Text to Image)
Image Generation is a challenging yet exciting CV task as it aims to produce novel images based on some input.
For clarity, there are different approaches to Image Generation. For example, you might have heard about Photoshop’s Content-Aware generative options that allow you to perform many transformations with images using AI using an original picture as input. However, the hottest topic in the community is generating images and objects via text prompts.

Source
If you feel like diving deeper into the Image Generation field, please check out such products as:
Image Super-Resolution
Image Super-Resolution (ISR) refers to the task of improving the input image’s quality and clarity by upsampling its pixels. It is often combined with Image Restoration (check out below).
In real life, ISR can be used to improve the quality of satellite imagery, enhance security cameras (for example, to recognize license plates or faces better), and so on. You can also apply Super-Resolution to the images in your dataset on other CV tasks to give the model a stronger training signal.

Source
Image Restoration
The Image Restoration task aims to remove noise, blur, and other artifacts that occur due to poor light conditions, insufficient camera capacity, or errors during image compression. It can be used as a part of the Image Super Resolution task as a pre-processing step.
A typical example of Image Restoration is recovering old photos and videos, such as historical or family archives.

Source
Image Captioning
In the Image Captioning task, the model takes an image as input and generates its textual description in natural language. Hence, this task combines CV and NLP (Natural Language Processing) fields. As you can imagine, the problem is challenging, as there exist many ways to describe one image, and the descriptions may vary by the level of detail or style.

Source
Use cases of Image Captioning include:
Creating assistants for visually impaired people;
Indexing images with textual meta-data for a more efficient search;
Generating descriptions of goods on e-commerce platforms;
Etc.
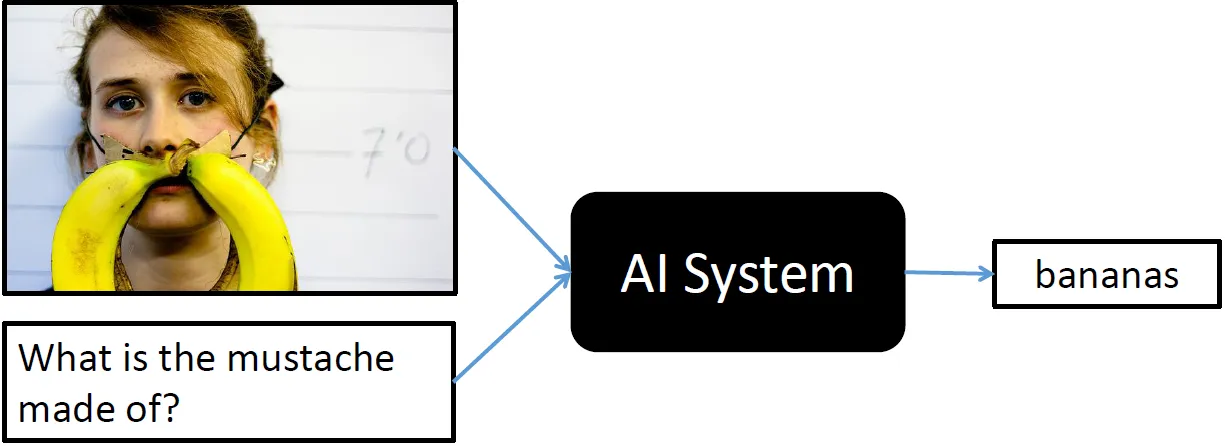
VQA (Visual Question Answering)
Visual Question Answering is another task that combines NLP and CV. In this task, developers teach models to understand the content of the image and be able to answer questions about the image in natural language.
Like Image Captioning algorithms, VQA models can assist people with visual impairments, help better search for relevant images or videos, enhance social media or education experience, etc.
Source
If you want to play with demo models, check out a Hugging Face page on Visual Question Answering.
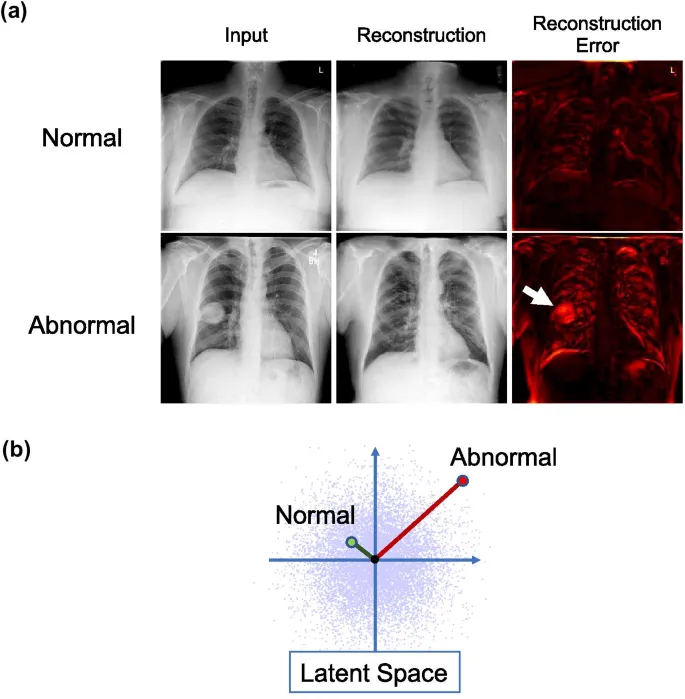
Image Anomaly Detection
Image Anomaly Detection or Outlier Detection or Novelty Detection is a binary Computer Vision classification task that aims to detect images that deviate from the expected pattern.
Examples of use cases include:
Detecting defective items in factory production;
Finding damaged crop samples in agriculture;
Revealing tumors or lesions in medical imaging;
Etc.
Source
Scene Understanding
The Scene Understanding task aims to analyze objects in context with regard to their surroundings. The scenes are usually in 3D and captured by various sensors and radars. Therefore, they better reflect complex spatial, semantic, and functional relationships between objects than 2D.
Often, Scene Understanding tasks are also dynamic and real-time. You can see some examples of its application in the image below.

Source
Feature matching
Feature matching or Image matching refers to the task of matching various images of the same object or scene. The task's difficulty is that the same objects might be presented in different angles and lighting conditions; they may be occluded, blurred, and so on.
The applications of Feature matching include:
Aligning the images (for example, to create panoramic photos);
3D reconstruction of objects;
Object Detection;
Camera calibration;
Motion tracking;
Robot navigation;
Etc.

Source

Source