Comprehensive overview of data augmentations in Machine Learning
The quality and the quantity of your data have a vast influence on your final model's performance. However, a big challenge that Data Scientists often have to overcome is the lack of sufficient training data, as well as the expenses associated with gathering it.
Data augmentation is a Machine Learning technique that helps to expand the existing scarce data and to boost the metrics.
You might consider using augmentations if you want to:
- Reduce the costs of gathering and labeling data;
- Improve the performance of your model with the existing data;
- Add more diversity to your training set.
Data Augmentations explained
Data augmentation in Machine Learning is a process of increasing the size and diversity of the dataset by creating new data points from the existing data. In Computer Vision, it can be done by altering the existing images in different ways, for instance, by rotating them or changing their brightness or hue. The neural network will perceive the altered versions as separate images and learn new things from them.
The reasons to use augmentations are the following.
1. Enriching the dataset
Whenever we collect images of some target objects, we try to be as representative as possible. For example, when we teach the model to recognize dogs in general, we try to include images of dogs of different breeds, colors, and so on in the dataset.
However, in the real world, the targets of our interest might appear in different positions, angles, sizes, and contexts. It is almost impossible or very costly to encompass all the variations in the dataset.

Source

Source
In this case, capturing all the possible angles and contexts in which the dogs might appear would be tough. Instead, we can use augmentations to add various alterations to our existing dataset. This could make the model robust towards real-world variations while saving the project budget.
2. Diversifying the dataset
Data augmentations can be useful even if you have a large dataset already.
For instance, imagine you want to build a classifier that distinguishes Bulldogs from Pugs. You gather thousands of images of both breeds. However, your model still does not differentiate them properly. Then you notice that all the Bulldogs in the images look to the left, and all the Pugs are standing with their heads to the right. Thus, the model has picked up on the most obvious yet inessential feature, which is the dog's position in space. Instead, it should have concentrated on more relevant features, such as the dog's color, body proportions, etc.

Source
This problem can be solved with the use of augmentations. A simple Horizontal Flip could be of great help.

Source
Data Augmentation workflow in Computer Vision
- Choose one or several augmentations;
- Set the parameters of chosen augmentations and apply them to the training set;
- When the augmentations are applied to the images, feed them to your model and start training.
How to use data augmentations in CloudFactory's AI Data Platform
To access the augmentations section in AI Data Platfrom, please:
- Open the Project Dashboard;
- Click on the Model Playground section;
- Select the split and create an experiment;
- In the experiment parameters, open the Augmentation Train section;
- Press the Add new transformations button and select as many augmentations as you want to apply. You can toggle the augmentations on and off or delete them;
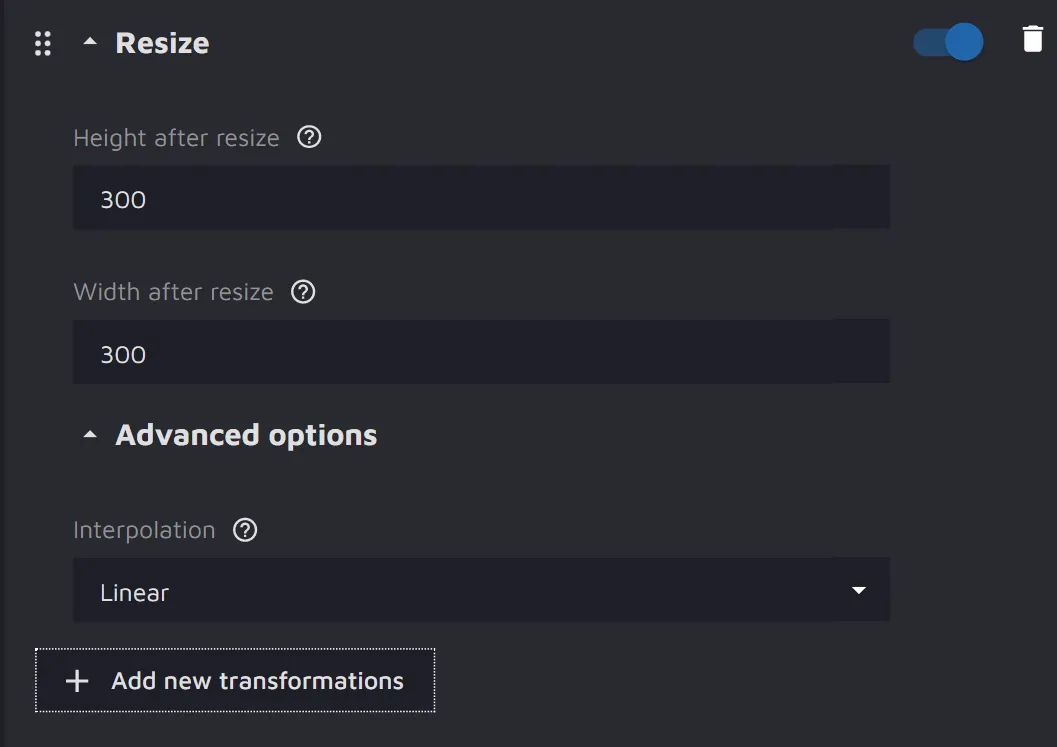
Source
6. Review the results of transformations in the section on the right.
- Click the first button (arrows) to apply the augmentation over again;
- Click the second button (dice) to change the displayed image randomly.

Source
Data augmentation on train Vs. Data augmentation on validation
Usually, augmentations are applied to the training set only. This is because validation and test sets are used for unbiased estimation of the model's performance, so they should consist of the original unchanged images. Thus, you can check whether your model performs well on real-world data and whether the augmentations helped it to generalize better.
However, you can also augment the images from your validation set. We advise doing so only if you are sure that some variation in the real-world data can be imitated well with augmentations.
How to choose the proper data augmentation
In general, augmentation use is project-specific. The best advice is to play around and see what better fits your case.
It might be a good idea to use several augmentation techniques at once, such as image cropping, rotation, color and brightness perturbations, etc.
Below are the augmentations that AI Data Platform offers: