Active Learning in Hasty
Your model’s success directly depends on the quality of your annotations. However, in reality, most datasets consist of raw unlabeled data. As a result, whole teams and departments end up spending hundreds of hours on data annotation, even for the simplest tasks.
Hasty already provides an environment with automated tools to speed up your annotation process. However, we wanted to directly address the need to label a vast amount of data.
To do so, we added the Active Learning feature to the platform. In short, it offers the user to label only the images the model is most unsure about instead of the whole dataset. This makes the annotation process more efficient and potentially improves your model’s performance – so you work smarter, not harder.
On this page, we will explore:
- The difference between Active Learning and conventional approach;
- Ways to prioritize your work queue using the Active Learning concept;
- Advantages and limitations of Active Learning.
Let’s jump in!
Active Learning Explained
To understand how Active Learning works, let’s first grasp the difference between Active Learning and the conventional approach.
In standard data annotation, the pipeline looks as follows:
- We gather raw data and pass it to an annotator;
- The annotator labels all the data;
- The model is trained.
As you see, a massive shortcoming of this method is that it requires us to label the entire dataset, which becomes painful and time-consuming as the size of the dataset grows.
This leads us to a question: do you really need to label the entire dataset? Most likely, you will have many raw images that will not improve your model significantly if labeled.
That’s why, with Hasty, you can not only apply Automated labeling to save time but also take advantage of the Active Learning (AL) feature. It uses an iterative algorithm that suggests the best images for the user to label (in the image annotation case). This might save tons of resources and time while having the potential to produce better results.
Active Learning pipeline: the Unlabeled Pool scenario
There are different ways to use Active Learning. The Unlabeled Pool scenario is one of the most common ones. This is how it works:
- We start with a large pool of unlabeled data and a small amount of labeled data;
- We train the model on the labeled data;
- The model assigns an informativeness score to the unlabeled images and ranks them from most high scoring to least;
- The most informative (high scoring) images are suggested for labeling;
- We annotate the proposed image(s) and add them to the training set;
- We train the model and repeat the process until we reach the stopping criterion. It can be the number of queried instances, iterations, certain performance thresholds, etc.
Ranking the instances: Uncertainty Sampling
You probably wonder: how exactly does the model understand which images are more informative than the others?
In Hasty, we employ the Uncertainty Sampling technique to detect the most informative (uncertain) instances. The logic behind it is simple: the more uncertain the model is about some image’s class, the more informative it would be to label it.
Think of this classroom example. The teacher gave you a task on a math topic you are familiar with, but there is one formula you do not know. Two scenarios may follow:
- The teacher explains the formula in a minute and lets you do your task;
- The teacher starts explaining everything from the very concept of algebra to the formula you were asking about.
Probably, it is more efficient when only the information you are unsure about is explained (Scenario 1) – and this is roughly how Uncertainty Sampling works.
The algorithm of Uncertainty Sampling is the following:
- The model predicts probabilities for different classes of new images;
- We run these probabilities through some acquisition functions or heuristics. They help the model to select the most informative unlabeled instances. Heuristics that we use in Hasty include:
- These heuristics spit out a number for an image;
- The numbers for every image let us rank images in order from "most uncertain for model" to "least uncertain." Most uncertain images are suggested for labeling first.
Active Learning VS Random Sampling
As an option, users can just label any image they want. This would be close to Random Sampling (assuming the user has no bias in picking images with certain content). This is also a valid heuristic, and oftentimes, one that is very hard to beat.
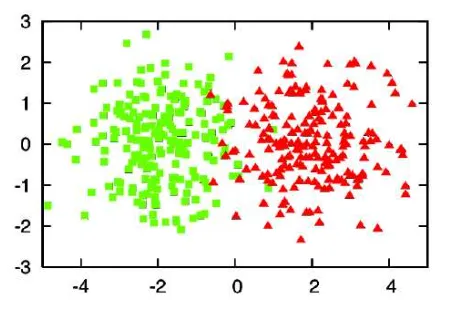
However, there are cases when Active Learning produces better results than Random Sampling. To illustrate the idea, let’s observe a toy example. Suppose we need a model that distinguishes between two classes – Cats and Milkshakes.

Source
Let’s say the real class distribution looks as follows:
Source
Based on that, we might suppose that the separation line should look somewhat like a slightly tilted straight line:
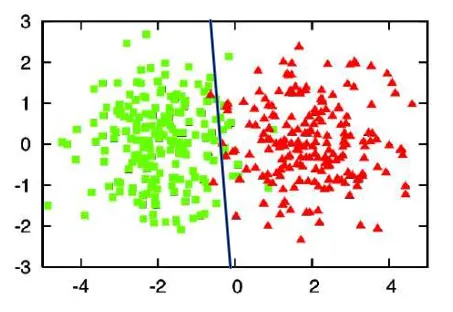
Suppose we can label only 28 instances to train the model. Which images should we choose?
In Random Sampling, as the name suggests, the user will label the images randomly. Here is what the separation line may look like:
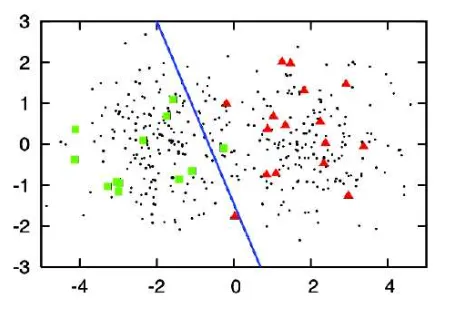
*dots = unlabeled instances
Source
The separation line we received is too tilted and does not reflect the actual distribution of classes perfectly. As you can see, random sampling does not guarantee high model performance.
In the Active Learning approach, we would try to label only the most informative, i.e. uncertain images. Labeling instances which are clearly cats or milkshakes is not very useful from the model’s perspective.
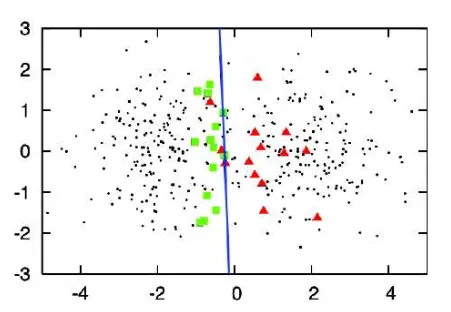
Source

Source
Exploration VS Exploitation
It would be dishonest not to mention one big caveat here: the problem of balancing Exploration and Exploitation in Active Learning.
Let’s take the case of self-driving cars. Imagine having around 1 million images in the dataset. How many should you rank?
There are two extremes you could go for:
- Complete Exploration: you can count probabilities for ranking for all 1 million images. However, it will be very costly in terms of time, money, and other resources – especially if you have to do so every time some new video feed comes in.
- Complete Exploitation: alternatively, you can get probabilities for only 1000 images and rank them. What about the remaining 999 000 images? Probably, you will leave out a better image that could be labeled, and your model will underperform.
This is one of the most challenging problems to balance. So far, Hasty uses predefined parameters to change the Explore vs. Exploit ratio for ranking. Currently, we run ranking on 100 images. However, this technique heavily under-explores if the number of unlabeled images is much greater than that number.
This will change as the feature matures. We plan to make these settings adjustable so you will be able to rank as many images as you need at a time. Moreover, you can simply label the 100 suggested images and run Active Learning again to receive new suggestions for what to label next.
How to choose the heuristic?
There is yet another issue. How do you know which Uncertainty Sampling method works best? Should you go for Margin, Entropy, Variance, or nothing at all?
While the right heuristic on the right data can yield significant improvement, the downside is that there is no way to know this in advance.
This is why Hasty retrains models in quick successions. This way, you can get almost immediate feedback on your choice of heuristic and adjust it if you do not notice improvements.
Summary
Active Learning is a technique that tries to choose the most useful data to label while omitting uninformative samples. The advantages of using Active Learning in Machine Learning are as follows:
- It helps to label data quicker and more efficiently;
- Can be used for Object Detection, Instance Segmentation, and Semantic Segmentation tasks;
- It might lead to better model performance in comparison to randomly selected data.
Potential drawbacks include:
- Finding the right heuristic for your project may demand some trial-and-error;
- The benefit of Active Learning is most visible when relatively few images are labeled. However, it diminishes somewhat as you label more images (around 500+).
In Hasty, we have integrated the Active Learning feature to deliver you the best annotation experience. The feature analyzes the dataset and suggests you the best images to label, saving your time and nerves.
Please check out our Active Learning tutorial to learn more.