Object Detection labels import
Imagine having an Object Detection dataset with the annotations in the COCO format. How would you import annotations in such a case? Well, you can simply follow the steps mentioned on the Import annotations (Beta) page. Let's see how it works.
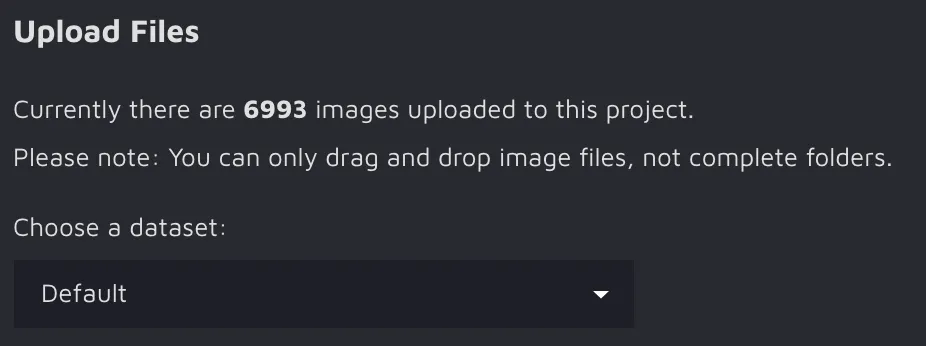
First, you need to create your Hasty project and upload images to it. These steps are straightforward and should not cause any trouble.
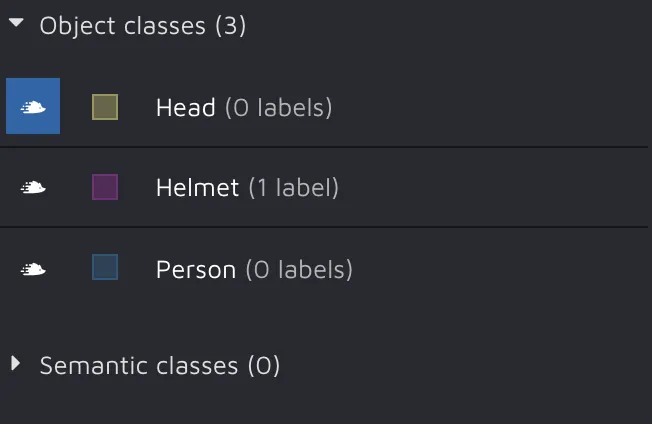
Second, you must create the label classes and attributes you will use in your project. Simply follow the guide from the documentation, and it will take you seconds to do.
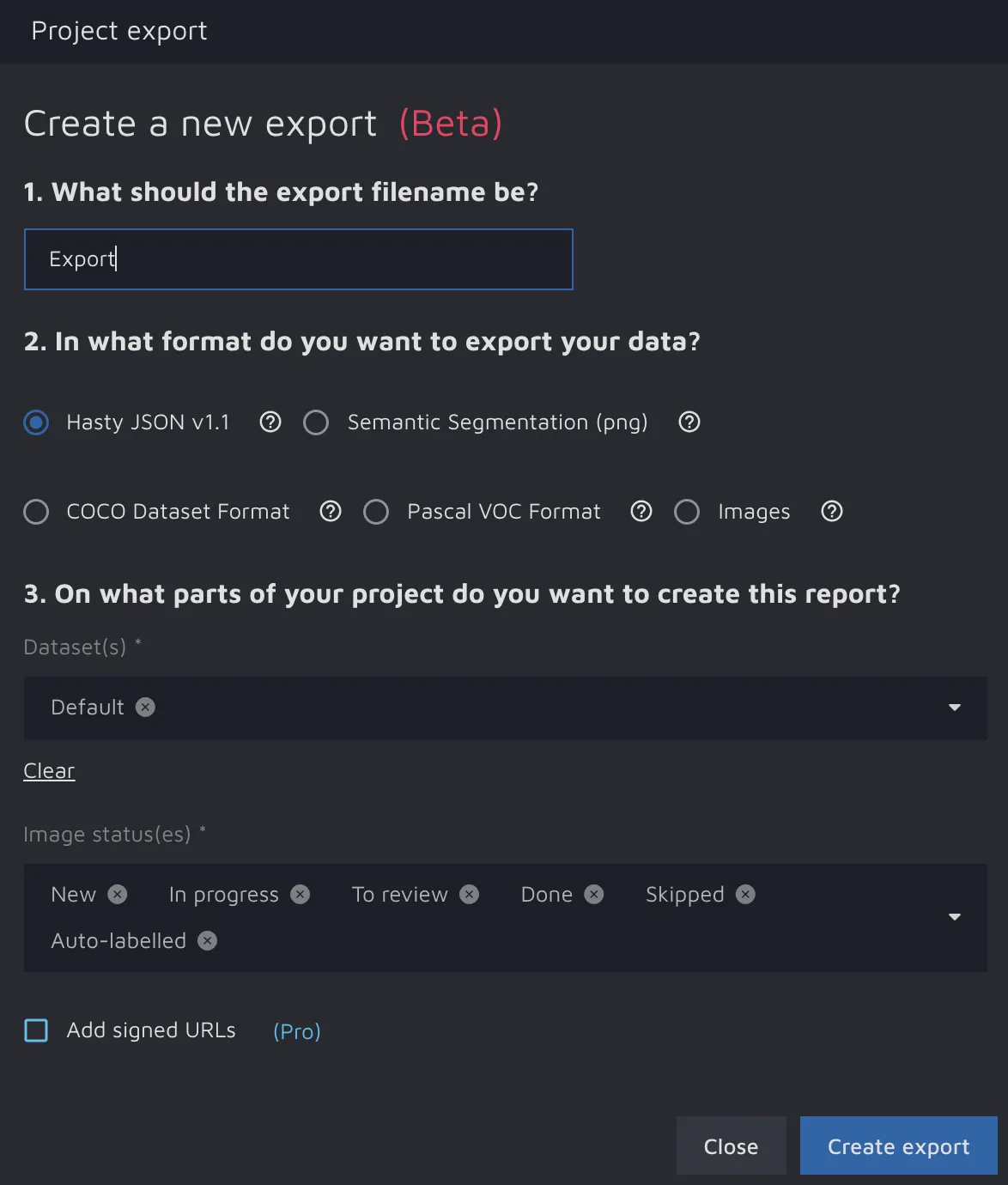
Third, export your project in the Hasty JSON v1.1 format through the Export data feature.
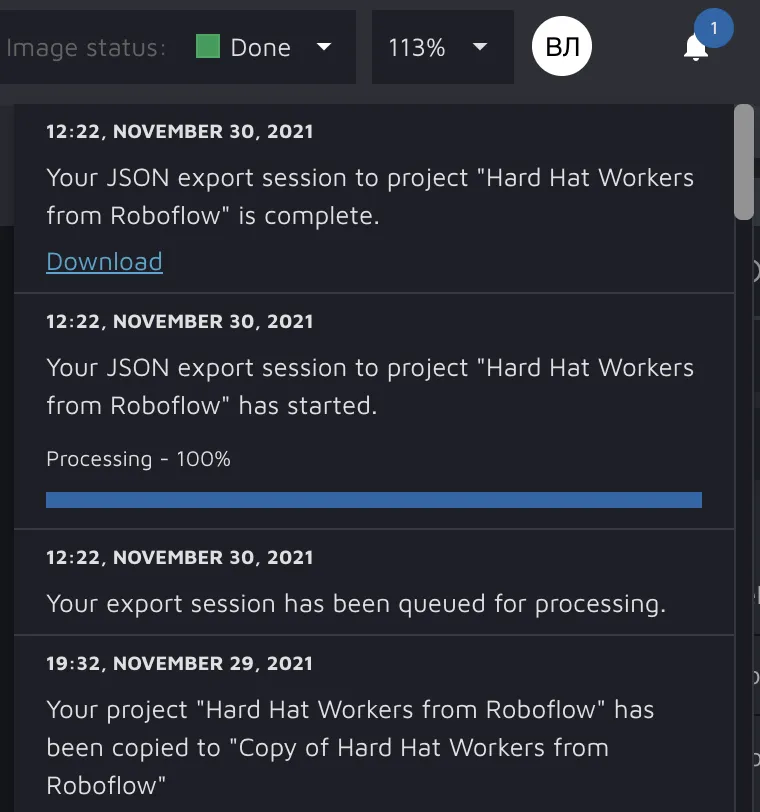
By clicking the notification button on the upper right side of the screen, you can download the result of your export session.
In the ZIP archive, there will be a JSON file containing the information about your project.
Since there are no annotations in your project yet, the list accessible by the 'labels' key for each image will be empty.
Please note that in Hasty JSON v1.1 format, all the information about images is stored as a Python list under the 'images' key. Also, images' data is represented in the form of a Python dictionary. So, annotations should be stored under the 'labels' key for each image. Let's expand our JSON file and add annotations to the corresponding images.
As mentioned above, your initial labels are in the COCO format, so it will require some coding to add the annotations to Hasty’s JSON file. However, if you are familiar with Python, it will not be a problem for you. Otherwise, please check the example script for converting COCO Object Detection annotations to Hasty ones below.
Now you have a JSON file in the Hasty supported format that contains all the annotations. To ensure that your file is ready to be imported, double-check whether it corresponds to JSON format. There are a lot of free online checkers that are up to the task, so you will quickly get the answer. If there is some error, return to your code and search for the mistake that messes up the JSON format.
The last step is to upload the expanded JSON file to the Hasty project. At this point, you have already done the most challenging part, so you can relax and enjoy the growing download and parsing percentage. If your import is successful, you will see the following picture.

Excellent, the annotations are imported, and you can start analyzing them with Hasty capabilities, for example, assure the quality of these labels with AI Consensus Scoring. Hopefully, this example and general import workflow will help you to import annotations to a project successfully.