Imagine having an Object Detection dataset with the annotations in the COCO format. How would you import annotations in such a case? Well, you can simply follow the steps mentioned on the Import annotations (Beta) page. Let's see how it works.
First, you need to create your Hasty project and upload images to it. These steps are straightforward and should not cause any trouble.
Second, you must create the label classes and attributes you will use in your project. Simply follow the guide from the documentation, and it will take you seconds to do. In our case, we have 404 images of Simpsons characters. The classes are the characters themselves - Homer, Marge, Maggie, Lisa, and Bart.
The COCO annotations for the dataset look as follows:
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
The only key in COCO annotations that is important for us is the "annotation" key. In Hasty JSON v1.1 format, all the annotation information (polygons, bounding boxes, classes, etc.) for each image is stored in the "labels" list inside each "images" instance. Filling the "labels" list with the corresponding annotations given in the COCO format is the key component for successful Import annotations (Beta) feature usage.
So, the third step is to export your project in the Hasty JSON v1.1 format through the Export data feature. This way, you will get a file in a necessary format that can be expanded with COCO annotations.
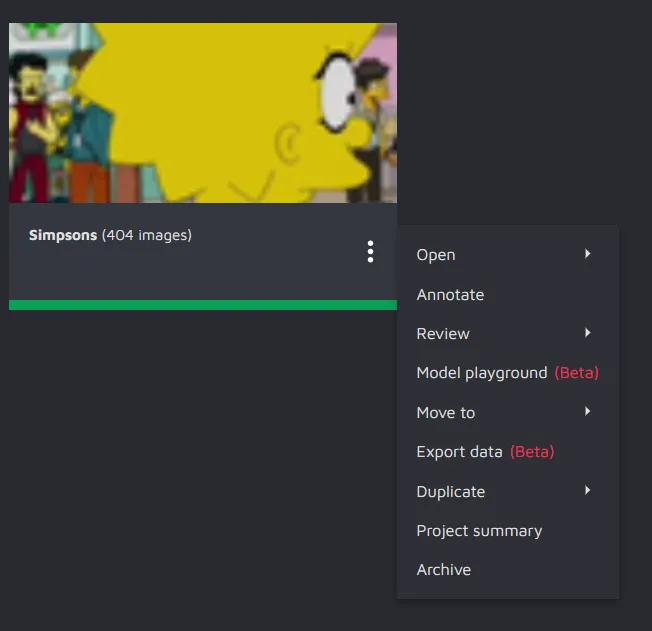
To export the project, just click on the three dots present in the
bottom right corner of the project and click on the Export data button.
By clicking the notification bell on the upper right side of the screen,
you can download the result of your export session. In the ZIP archive,
there will be a JSON file containing the information about your
project.
This is what each instance in the "images" dictionary should look like:
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
Please notice that the "labels" list is empty because there are no annotations in the project so far. The goal is to fill the "labels"
list for each image using the COCO annotations. You need to do some
coding to copy the annotations from one file to another to succeed. But
do not worry. We have your back covered.
As a programming language, we suggest using Python. Let's start by loading the COCO annotations file.
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
python
f = open("instances.json") # instances.json is the COCO annotations file
dat = json.load(f)
f.close()
The next step is to extract the annotation ids and image ids associated with each of the annotations from the imported file.
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
python
annotations_id = [dat["annotations"][i]["id"]
for i in range(len(dat["annotations"]))]
img_id = [dat["annotations"][i]["image_id"]
for i in range(len(dat["annotations"]))]
Then, we suggest creating a dictionary that stores the relevant information about the specific annotation for each image.
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
python
temp = defaultdict(list)
for delvt, pin in zip(img_id, annotations_id):
temp[delvt].append(pin)
# **temp** contains a dictionary that associates the images with their annotations# the key is the image id and the values are the annotations id.
With that done, you can now store the annotations for each image in a format that Hasty will accept.
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
python
annot_each = []
allannot = []
ann = dict()
for keys in temp:
for a in temp[keys]:
ann["polygon"] = restructure_polygon(
dat["annotations"][a-1]["segmentation"])
ann["polygon"] = ann["polygon"].tolist()
ann["class_name"] = cat[dat["annotations"][a-1]["category_id"]]
annot_each.append(ann)
allannot.append(annot_each)
annot_each = []
ann = {}
In the code block above, we create a new instance with the "polygon" and "class_name" field in the "labels" list. Notice that the polygon structure is different in Hasty and COCO. The COCO format has the following structure of polygon:
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
Whereas Hasty wants the polygon to look like this:
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
The class name is extracted from a dictionary called "cat" that contains the indices with the character's name.
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
At this point, the only task remaining is to add the annotations to the exported file.
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
python
filename = "simpsons_export.json"with open(filename, 'r')as f:
data = json.load(f)
i = 0for vals in data["images"]:
vals["labels"] = allannot[i]
i = i+1
filename2 = "annotated_simpson.json"with open(filename2, 'w') as f:
json.dump(data, f, indent=4)
We iterate through the empty labels of our original file, "simpsons_export.json", and replace them with annotations present in the allannot variable. Then we write this data in a new JSON file called "annotated_simpson.json".
The entire code looks like this:
Hello, thank you for using the code provided by CloudFactory. Please note that some code blocks might not be 100% complete and ready to be run as is. This is done intentionally as we focus on implementing only the most challenging parts that might be tough to pick up from scratch. View our code block as a LEGO block - you can’t use it as a standalone solution, but you can take it and add it to your system to complement it.
python
import json
import numpy as np
from collections import defaultdict
defrestructure_polygon(polygon):
polygon = np.array(polygon)
reshaped_pol = np.reshape(polygon, (-1, 2))
return reshaped_pol
f = open("instances.json")
dat = json.load(f)
f.close()
cat = dict()
cat[1] = "Homer"
cat[2] = "Marge"
cat[3] = "Maggie"
cat[4] = "Lisa"
cat[5] = "Bart"
annotations_id = [dat["annotations"][i]["id"]
for i in range(len(dat["annotations"]))]
img_id = [dat["annotations"][i]["image_id"]
for i in range(len(dat["annotations"]))]
temp = defaultdict(list)
for delvt, pin in zip(img_id, annotations_id):
temp[delvt].append(pin)
annot_each = []
allannot = []
ann = dict()
for keys in temp:
for a in temp[keys]:
ann["polygon"] = restructure_polygon(
dat["annotations"][a-1]["segmentation"])
ann["polygon"] = ann["polygon"].tolist()
ann["class_name"] = cat[dat["annotations"][a-1]["category_id"]]
annot_each.append(ann)
allannot.append(annot_each)
annot_each = []
ann = {}
filename = "simpsons_export.json"with open(filename, 'r')as f:
data = json.load(f)
i = 0for vals in data["images"]:
vals["labels"] = allannot[i]
i = i+1
filename2 = "annotated_simpson.json"with open(filename2, 'w') as f:
json.dump(data, f, indent=4)
Excellent, it is time to import the annotations!
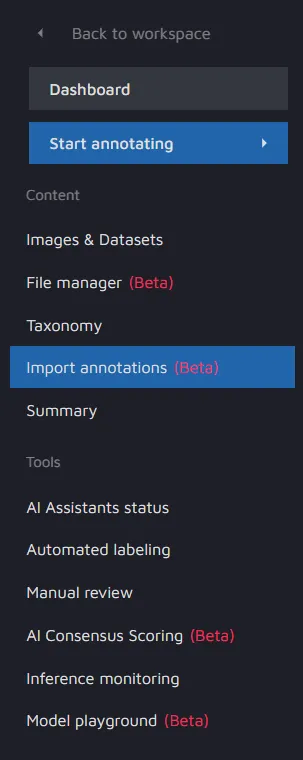
Go to the project dashboard and click on the Import annotations (Beta) button.
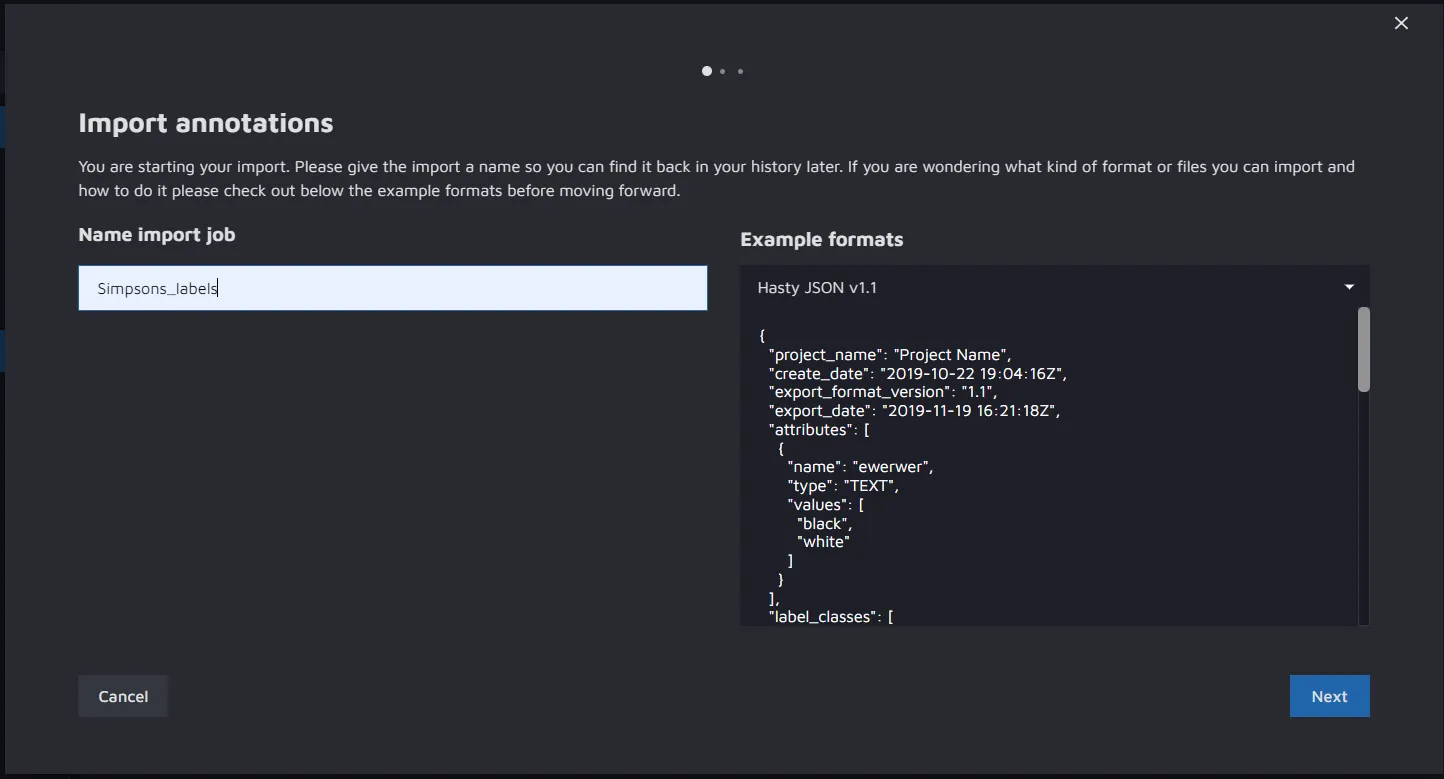
Then create a new import and upload the expanded file in the Hasty JSON v1.1 format.
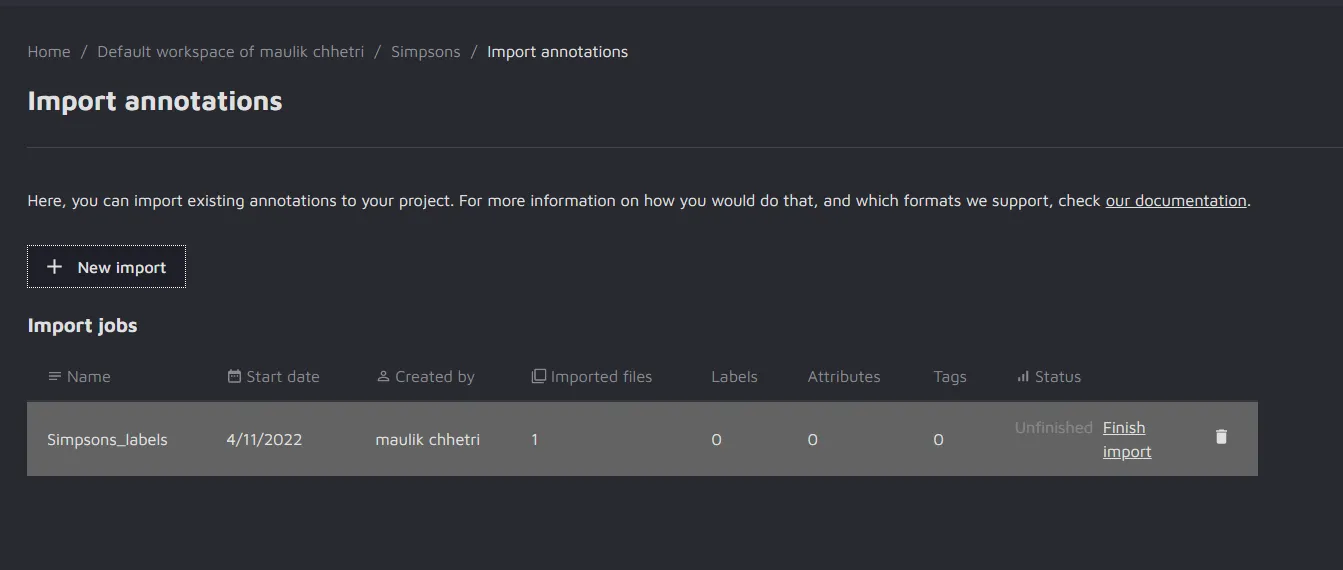
In our case, we named the import "Simpsons_labels". After the file is uploaded and checked, the import job will appear in the Import Jobs.
When the import is complete, the annotations will show up in the annotation environment.
Awesome, the labels are at their place! Also, please notice that all the annotated images are marked as "Done". This is the default setting for the import jobs but you can change it if you feel like it is needed.
Boost model performance quickly with AI-powered labeling and 100% QA.