Object Detection Assistant
The object detection assistant is one of our AI assistants. This assistant will help you with finding, creating, and labeling bounding boxes in a specific image - in short everything you need when you are preparing data for object detection.
It can be selected by pressing the toolbar icon:

or by pressing “J”.
Important: The assistant will not be available when you start a new project. The reason for this is that to work, the model first needs data. That data is the annotations that are made in a project. We start training the tool after you have set 10 images to "Done" or "To review".
Using the assistant
The assistant is straightforward to use. When selected, you will see shapes with an orange dotted border like this:
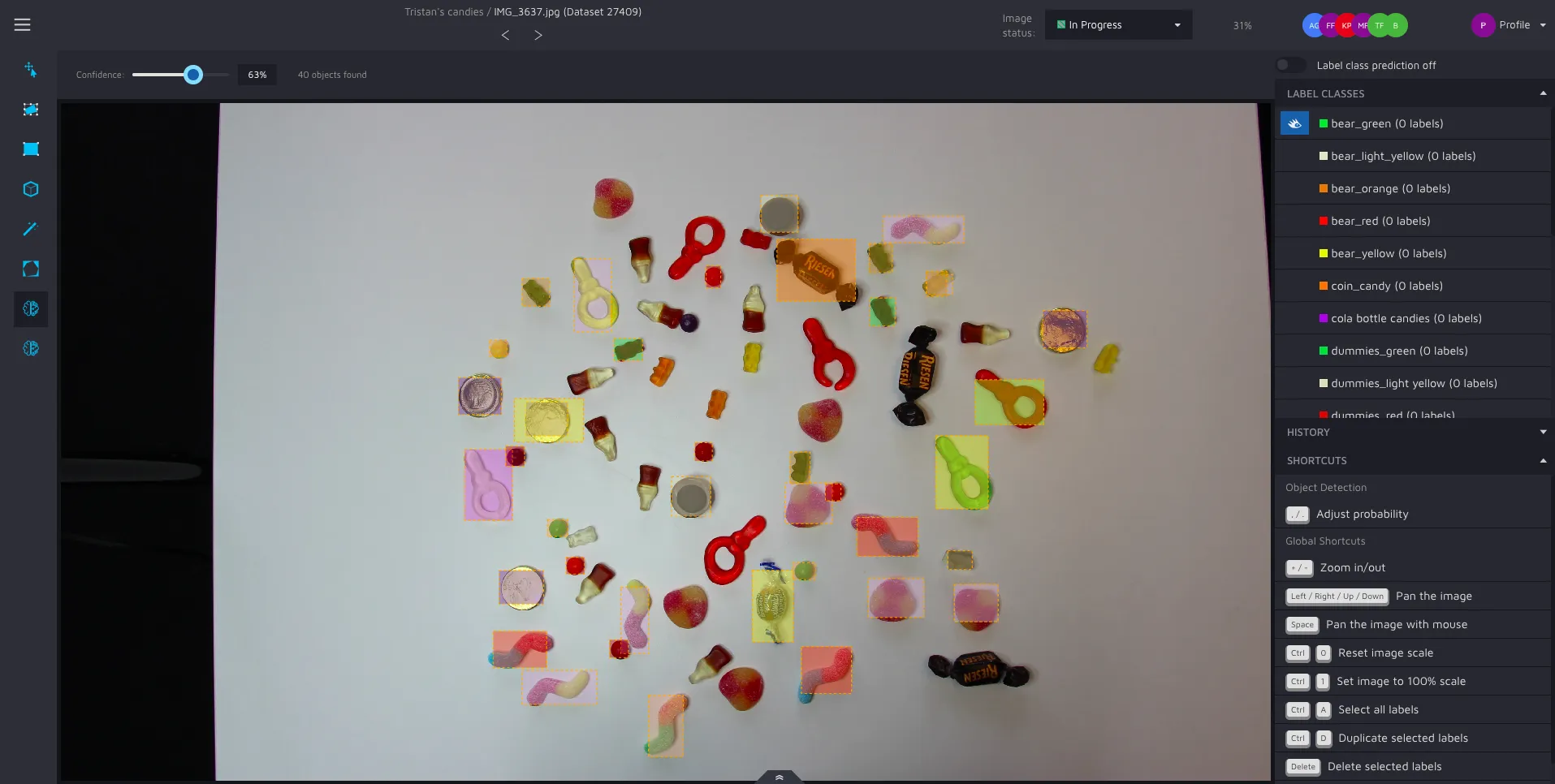
Notice that these shapes can have different colors. These colors are the same as your label classes, but a bit more transparent. What you are shown here are potential objects that our model has found in your image, and what label class the algorithm think the object has.
For you as a user, the only thing you have to do to accept our algorithm’s suggestion is to left-click on the shape you want to convert into an object. Every accepted object also gets a label class automatically assigned to it.
You can also accept all suggestions, as we do in the GIF above, by pressing "enter".
Please note that all suggestions can be edited after you've accepted them. Just select the annotation using the move/edit tool and edit them to your satisfaction.
If you don’t see any shapes or if they are not covering the objects in the way that you want, you can adjust the confidence modifier.
A primer on how models improve over time
You might be underwhelmed by the first results from our assistants. This is perfectly normal. What makes Hasty different, is that our AI assistants improve the more data they see. After 10 images, you might have a 10% assistance rate (percentage of annotations created by assistants). This is fine. When you've annotated 100 images, it might be 40-65%. When you have thousands of images annotated, we can offer very high percentages of automation - everything from 98% to 92% - depending on the use case.
The models retrain after having seen 20% more data. That means a new training is initialized after 12, 15, 19 images etc.
Confidence
This modifier controls which potential bounding boxes you are shown. The higher the confidence value, the fewer potential boxes you see, but those rectangles are the ones that our model is the most confident in. The modifier can be changed by adjusting the value in the tool settings bar or by using the hotkeys “,” and “.”.
**
To see this assistant in action, check out our object detection page on our website.
You can also check out our MP wiki for object detection if you are interested in creating and experimenting with models.**