AI Consensus Scoring
AI Consensus Scoring (AI CS) is our AI-powered quality assurance feature. In short, it uses a variation of AI models to find potential annotation errors in your dataset. Those errors are then presented to you with the suggestion of a correct (as AI thinks) annotation. From there, you can do one of three things:
- Accept the suggestion;
- Reject the suggestion;
- Or, if the error was correctly identified, but the suggestion needs optimization, edit the annotation manually.
We built this feature as we realized how much time annotation teams spend on quality assurance (QA). In some cases, QA took up to 40% of all time spent on annotation. This happened because finding errors consumed more time than actually correcting them, and annotation teams had to go through and review every single image by hand.
AI CS addresses this issue by finding all the potential errors automatically so that you can focus on fixing errors instead of spending hours detecting them.
How to access AI Consensus Scoring
You can access AI Consensus Scoring in the burger menu on the left or in the project Dashboard.
Creating a run
A run, or a sweep if you prefer, is when we use AI to perform a quality assurance (QA) check on all annotations in a project. To put it simply, we see how confident our model is in the correctness of the existing annotations.
To create a new run, click the Create new run button.
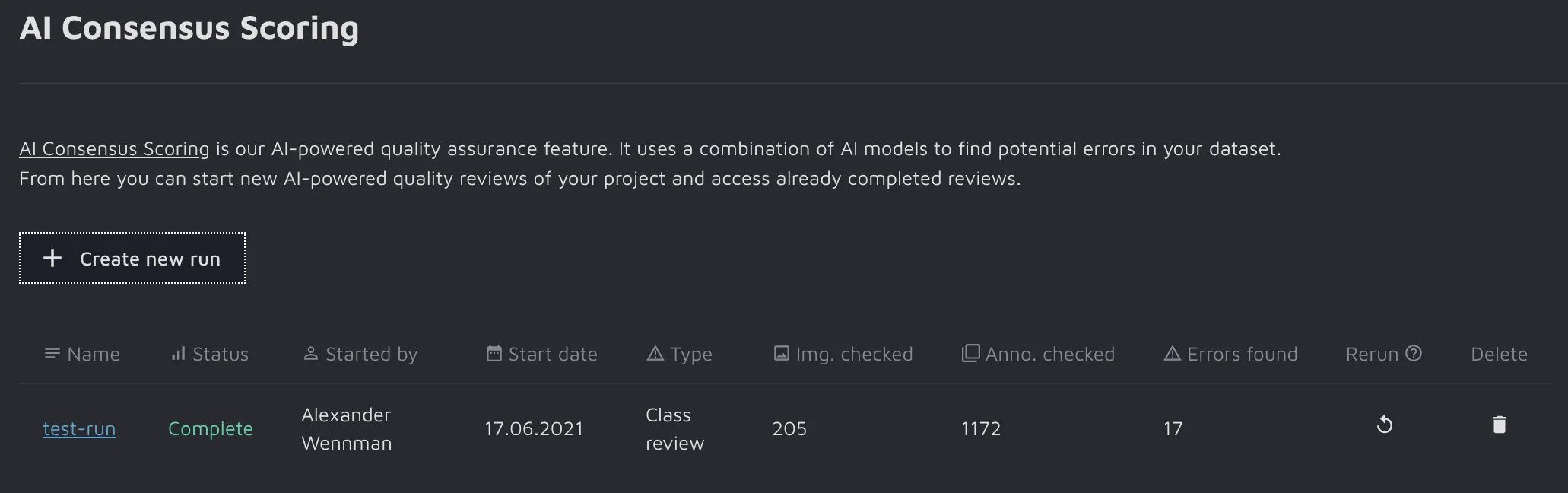
This will open up the "Create a new run" window.
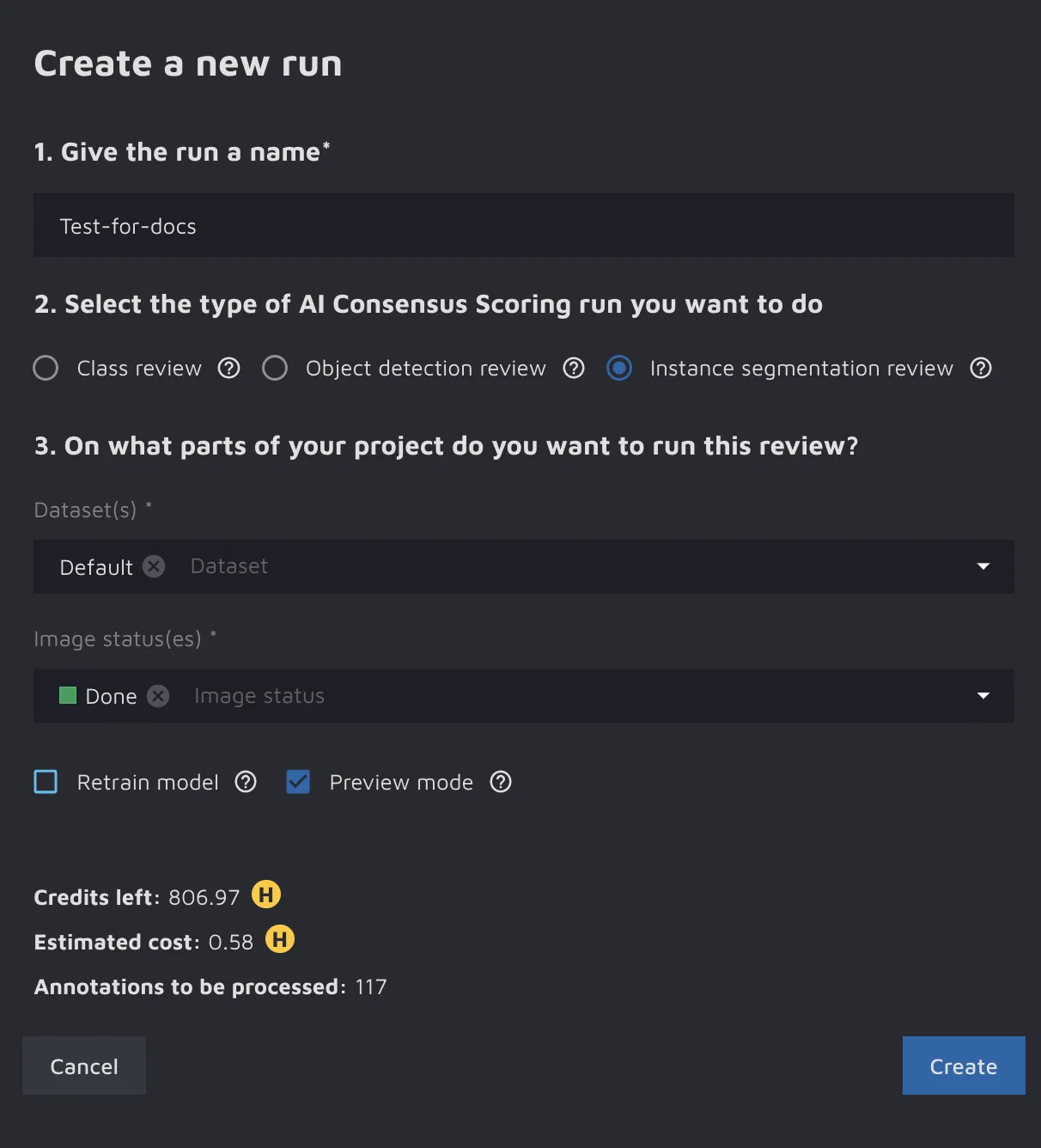
You should do the following:
- Name the run. It is a good idea to choose a name you can recall in the future, for example, the date of the run.
- Select what type of run you want to make. At the moment, you can choose from the following:
- Class review - this type of run reviews the correctness of the class labels (for example, Cat/Dog/Fish, Adult/Child, etc.);
- Object detection review - this run reviews the annotations for the Object Detection cases where the annotations are in the form of bounding boxes;
- Instance segmentation review - this run reviews the annotations for the Instance Segmentation cases where the annotations are in the form of polygons and masks.
- After deciding on what type of run you want to create, you need to select which data you want to check. You can do so in two ways:
- Select specific datasets that you want to check;
- Select the images with a specific image status.
- Finally, you have two additional options. Those are:
- Retrain model - this retrains the AI CS model from scratch. You might want to use it if you have added a substantial amount of new data since the last AI CS run;
- Preview mode - if you switch this option on, you will only be able to see 10% of the potential errors AI CS found. You will also only be charged 10% of the cost. If you find the results to be good, you can unlock all potential errors later.
After you've specified all options, click on Create button to start the run.
After having done so, you will go back to the overview. The run will be visible, and its status will be "Initializing.”

When the run has been completed, you will receive a notification, and the status of the run will change to “Complete.”

Results
When the run has been completed, you can click on it. You will see the Results page with detected errors and suggestions.
The page layout might vary depending on the type of AI CS run.
Class review run results
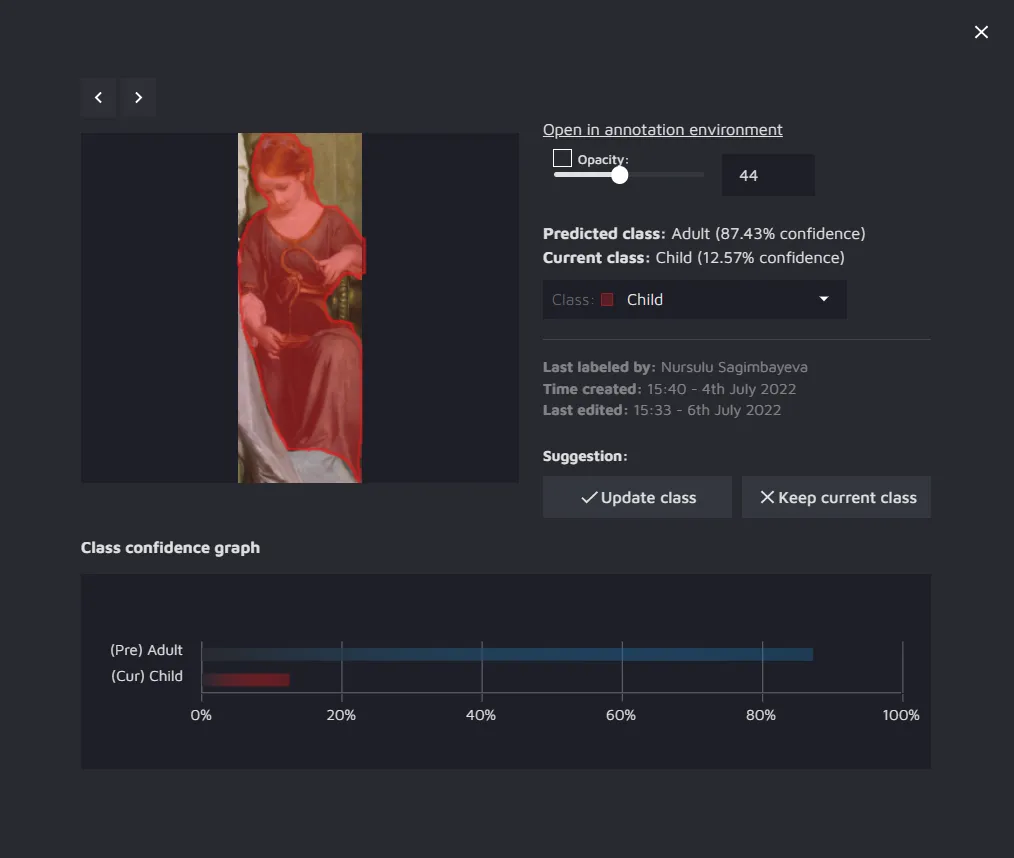
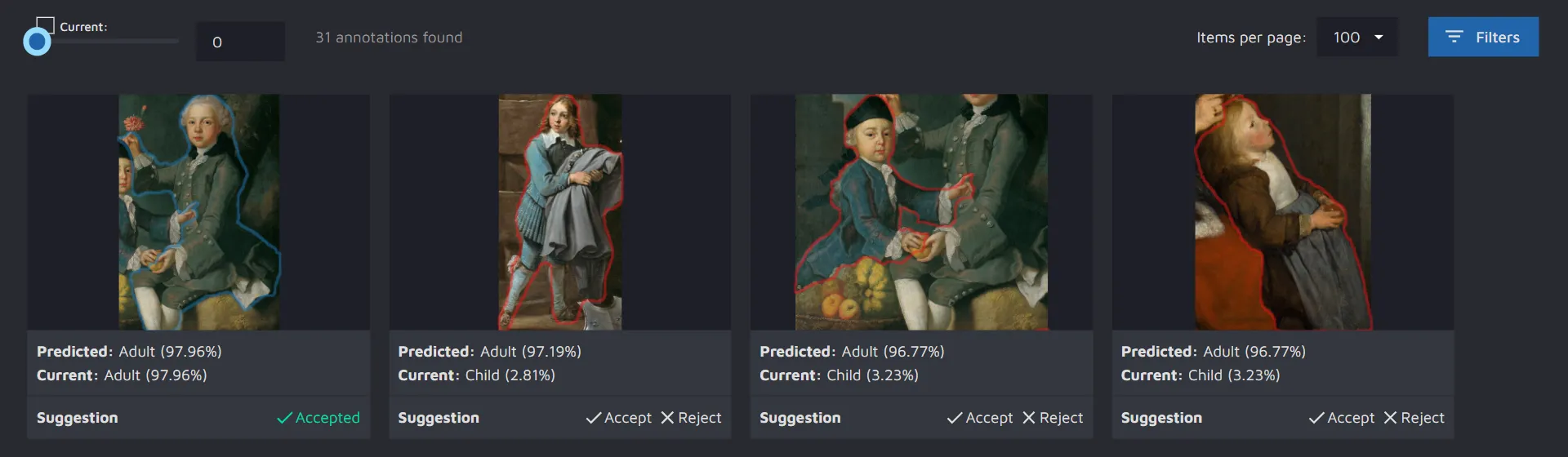
If you had run a Class review, you will see the predicted labels and current labels along with the model’s confidence score for each label. You can accept the model’s suggestion or reject it. If you accept the suggestion, the class will be automatically updated for the displayed annotation.
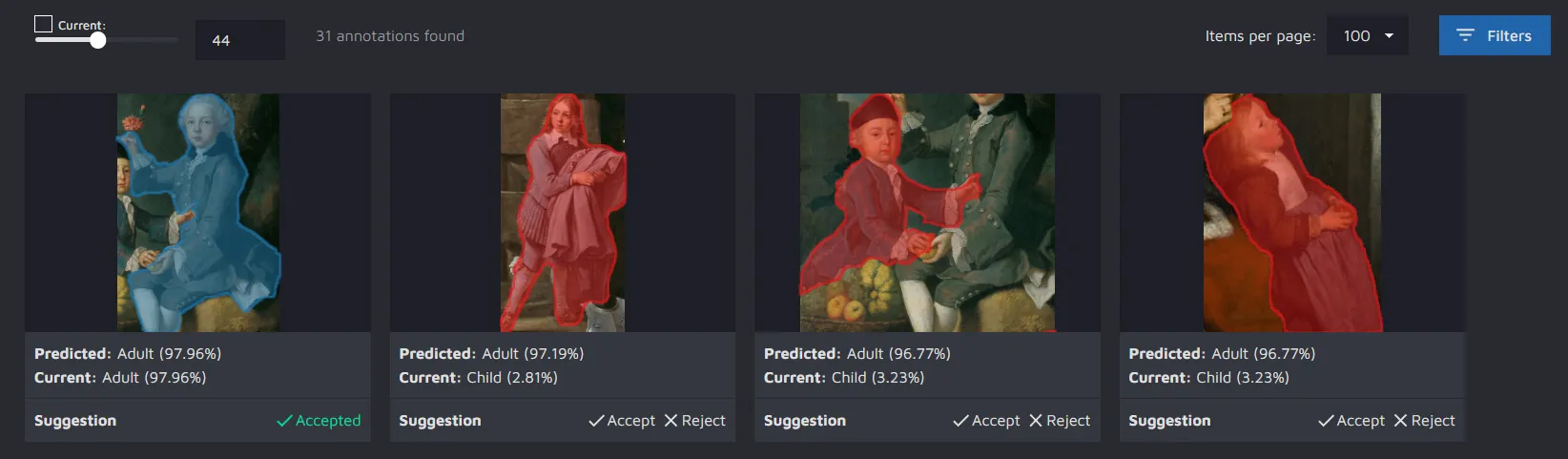
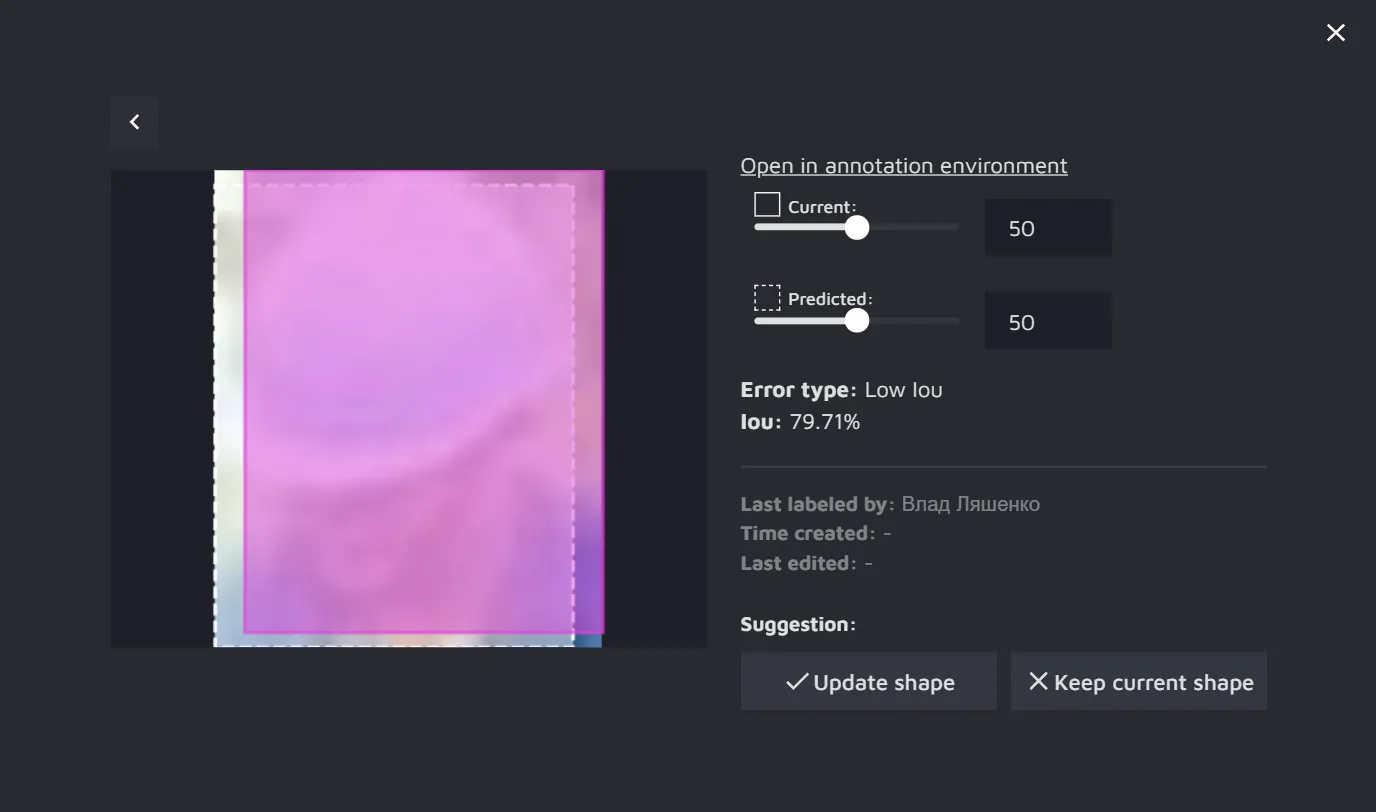
If you click on the image, you will get some more detail on the annotation and how the model "sees" it. For instance, in the example below, the model was 12.57% sure the person in the image is a Child and 87.43% sure it is an Adult.
You can also see some metadata on when the annotation was created and who created it.
Object detection/ Instance segmentation review results
If you have run an Object detection review or Instance segmentation review, there are three types of errors the AI CS can detect for these tasks:
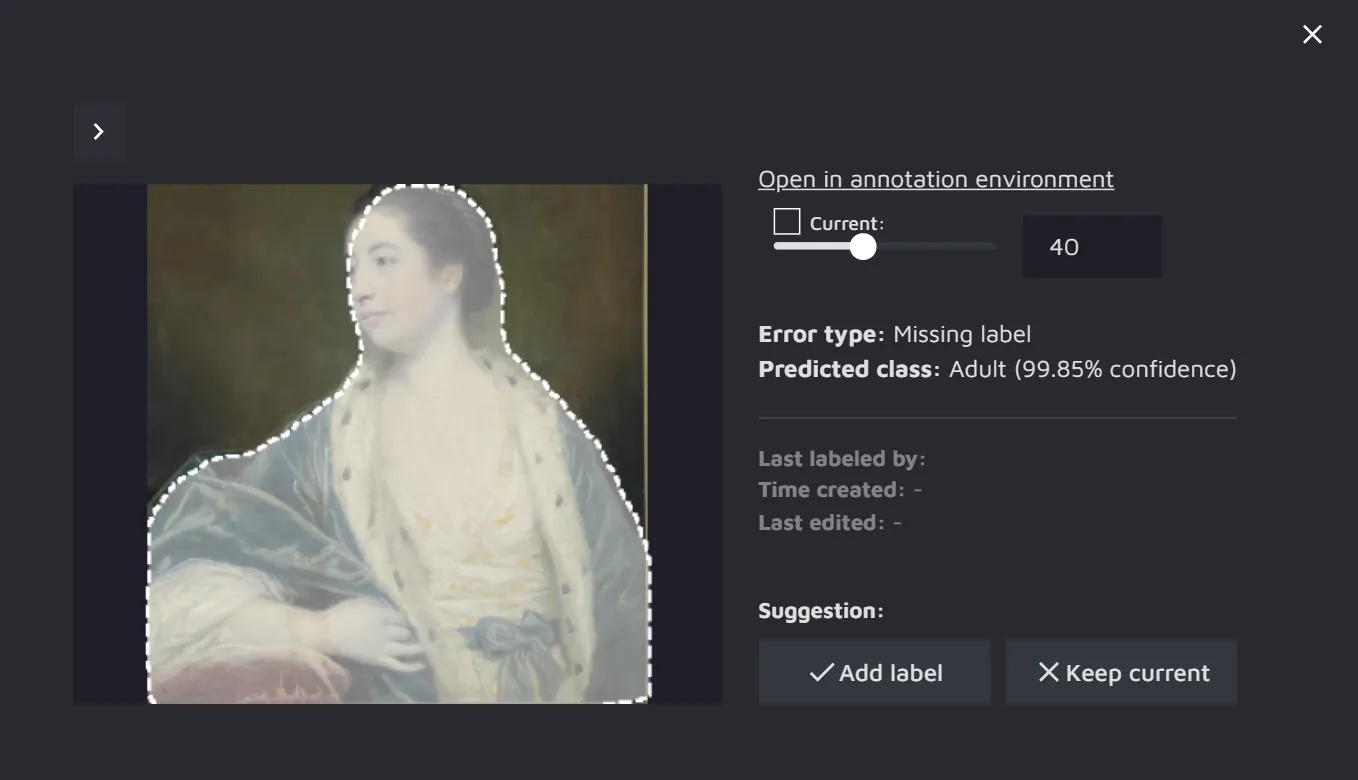
- Missing label - the model suggests annotations for where it believes they should exist.
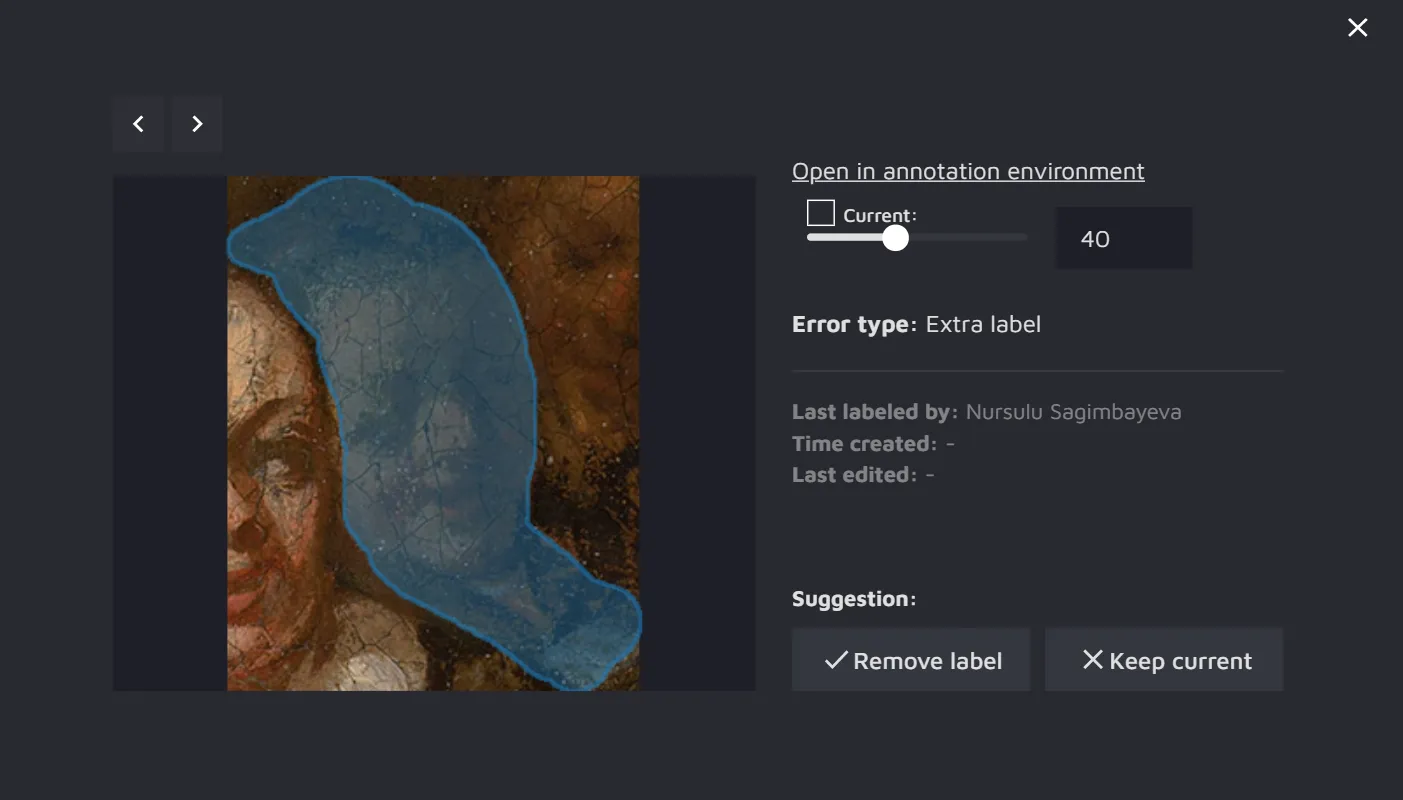
- Extra label - if there is some annotation that the model believes should not have existed, this will also be marked as an error.
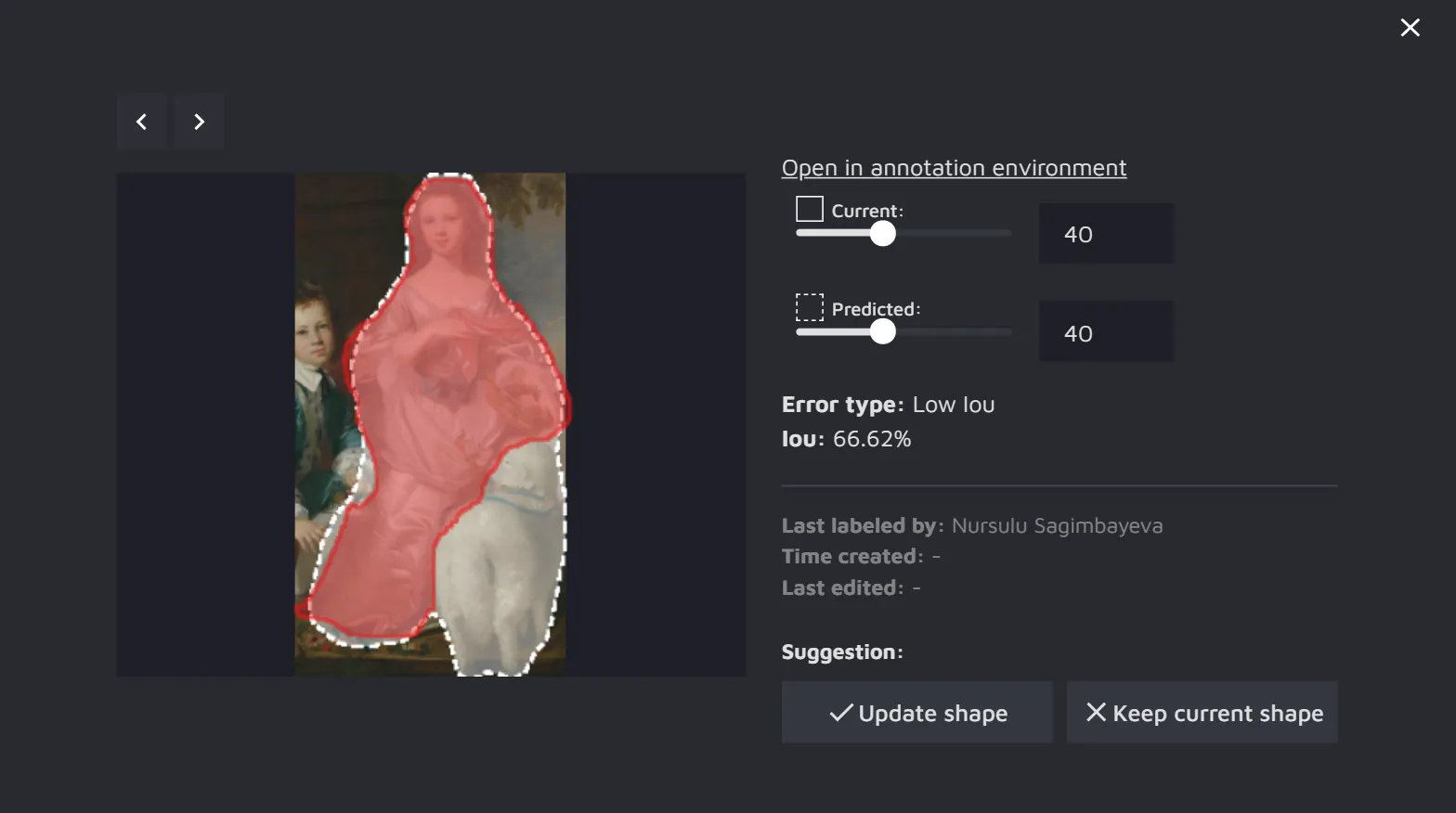
- Low IoU - if the existing annotation and the annotation predicted by the AI CS model overlap too little (have a low Intersection over Union), it will be marked as a potential error.
For the Instance segmentation review, the IoU is compared between object masks, whereas for the Object detection review, the IoU is measured between the bounding boxes.
Advanced settings
In the top-left corner, you will find an opacity controller through which you can manage the opacity of the annotations in the image. It can vary from transparent annotations where only the boundaries are visible to annotations completely filled in with color.
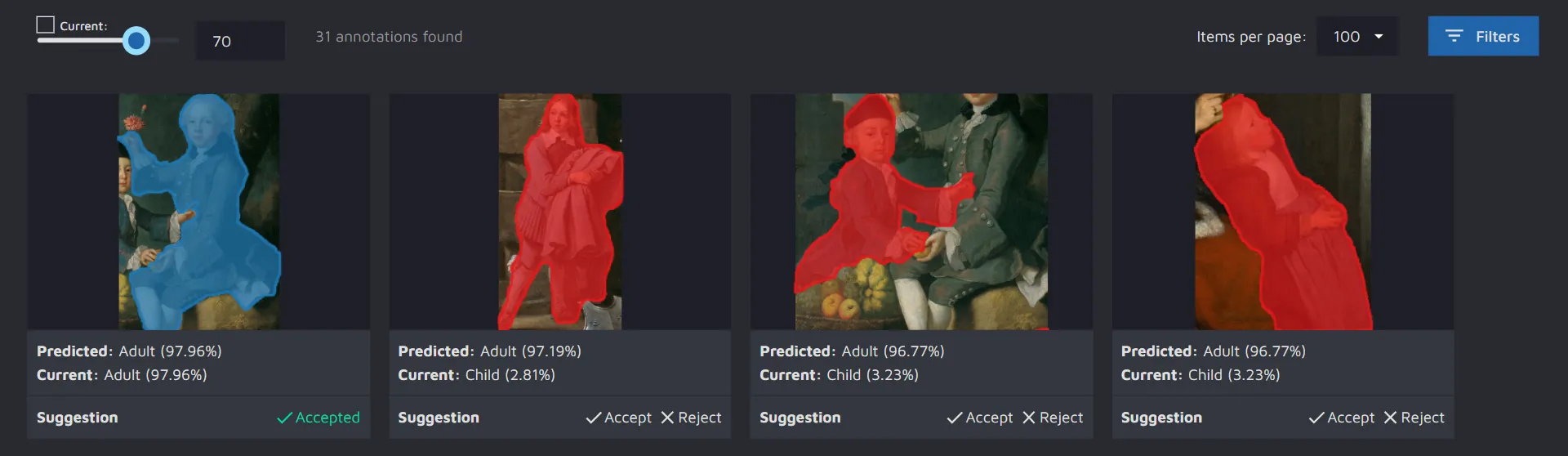
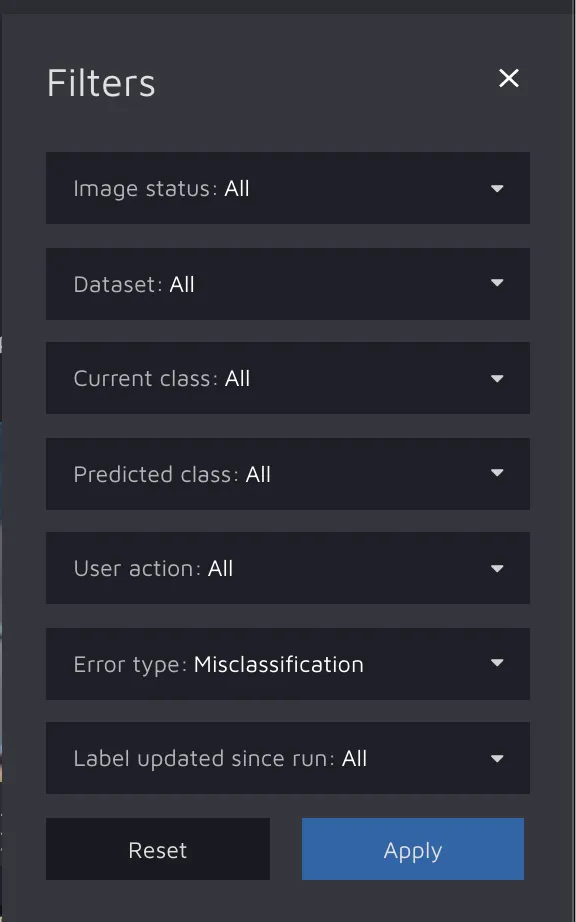
In the top-right corner, you can adjust how many potential errors you want to see per screen. You can also set up different filters in the Filters panel. Filtering can be very helpful when you have a large project with many possible errors and you want to navigate between them.
Summary
Along with the results, you can review the summary of the AI CS run.
There are different types of summaries Hasty AI CS offers.
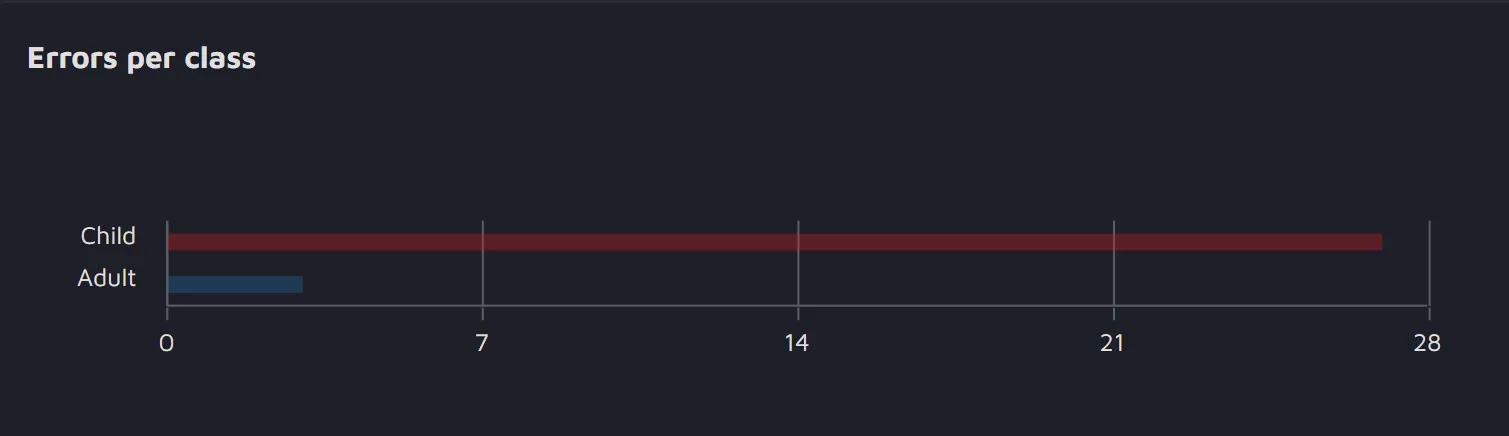
- Errors per class - the graph represents how many errors per each were detected by the model.
This feature is available only for the Class review run.
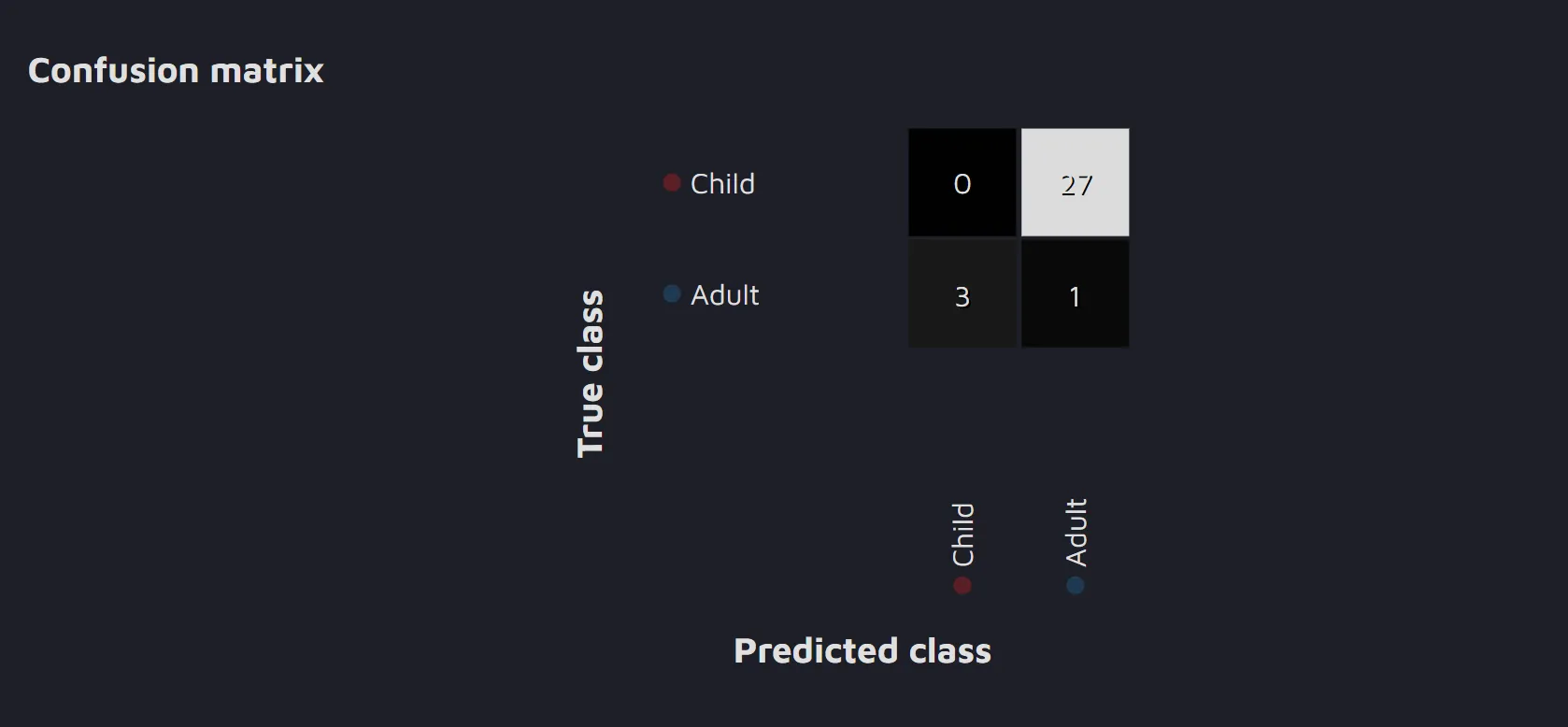
- Confusion matrix - the table reflects how many True and False Positives and Negatives the model detected.
This feature is available only for the Class review run.
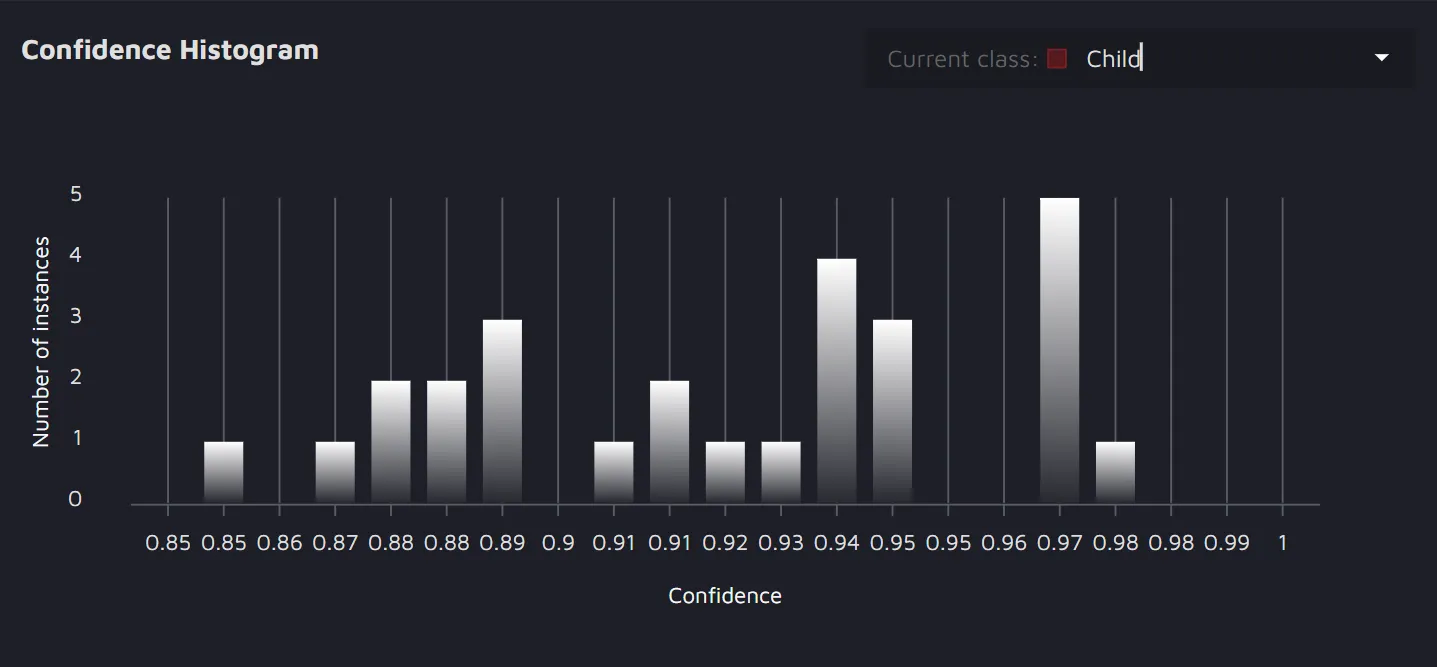
- Confidence Histogram - the histogram represents how confident the model is with the predictions it made when identifying potential errors for each class. For example, for the Child class, you can see that the model was 95% confident about its predictions in 2 cases, 77% confident in 1 case, and so on.
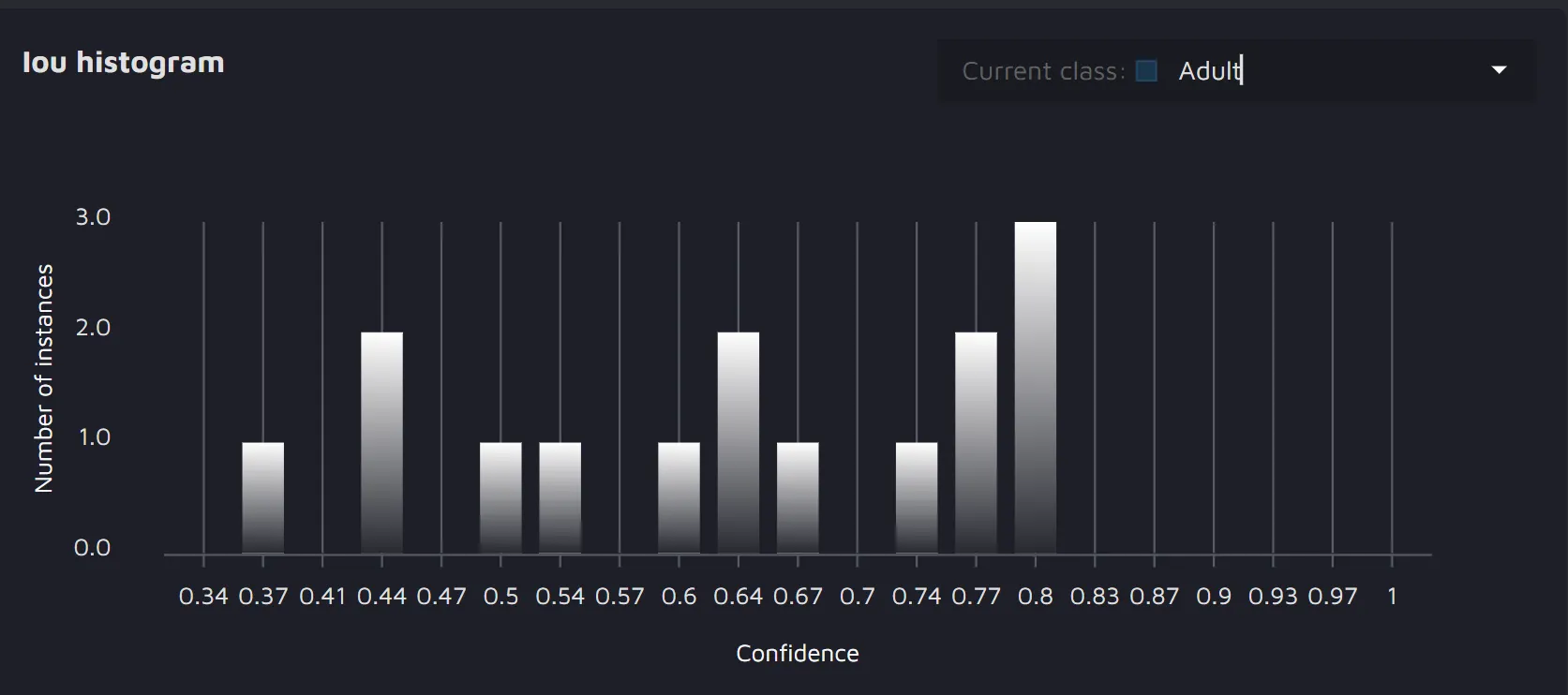
- IoU histogram - the histogram reflects the IoU frequencies between the existing and predicted annotations for each class. For example, for the class Adult, the IoU was around 80% three times, around 44% two times, and so on.
Using AI Consensus Scoring to improve your model
Another benefit of using AI CS is that you get a better understanding of how the model processes your images. For example, looking at our paintings project, we can see the following:
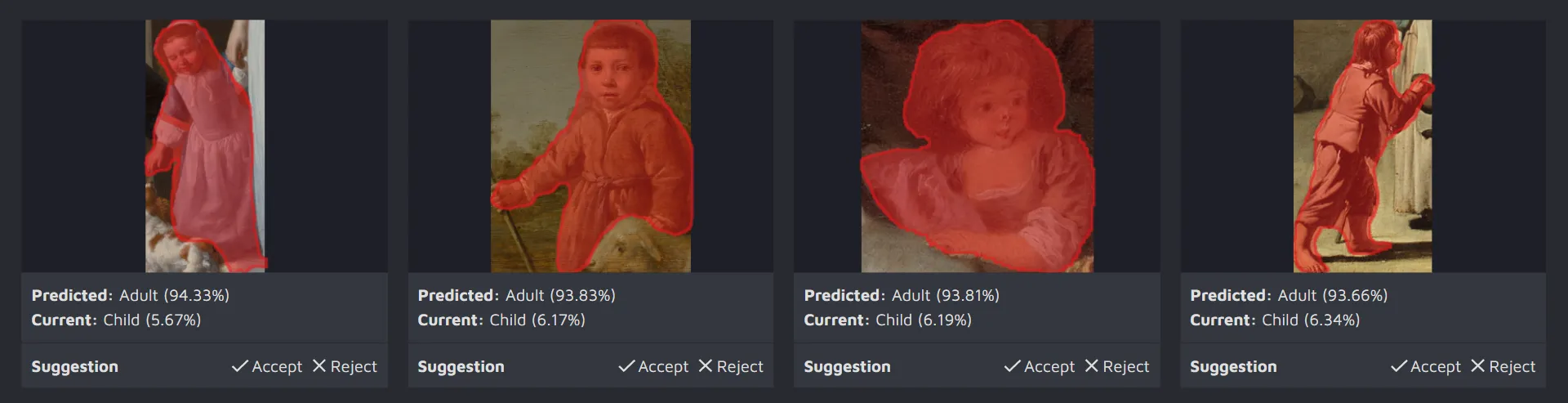
It is easy to notice that the model often predicts the Adult class where, in fact, a child is portrayed. Based on this information, we might assume that there might be a class imbalance in our data, and we should add more images with the Child class to our training set.