D-RISE
In the modern world, neural networks are a proven instrument for solving different tasks across various industries. With the development of high-level Machine Learning libraries and Deep Learning frameworks, it became easier to train a network and achieve a nice metric value. Still, boldly relying on a model that produces accurate predictions is not the best strategy. The key to success is a bit deeper and lies in understanding why a model makes a specific decision. This is where the D-Rise algorithm that makes the difference comes into the mix.
On this page, we will talk a bit about the D-Rise concept and its capabilities. Let’s jump in.
D-Rise explained
It is not a secret that the predictions of convolutional neural networks (CNNs) can be interpreted using saliency maps (heatmaps that show which regions of the input are more important for the model’s prediction). Unfortunately, when it comes to evaluating a network trained to solve Object Detection or Instance Segmentation task, such a straightforward method fails to produce high-quality explanations.
This happens because areas important for detecting or segmenting a particular object might not coincide with the object itself. For example:
A network can use contextual information;
Or some object parts might be more important than others.
Detector Randomized Input Sampling for Explanation (D-RISE) is designed for Object Detection and Instance Segmentation explainability purposes. It is a “black-box” method, meaning that D-Rise requires only the input and output of your model. In other words, D-Rise does not need to know your model's architecture, weights, and other parameters to work. Such a concept is a significant strength for an explainability method. With such a philosophy, D-Rise can be effectively applied for various object detectors, for example, one-stage (YOLO, SSD, CornerNet) and two-stage (Faster R-CNN).
So, given the input and output of your model D-Rise will produce a saliency map as a result.
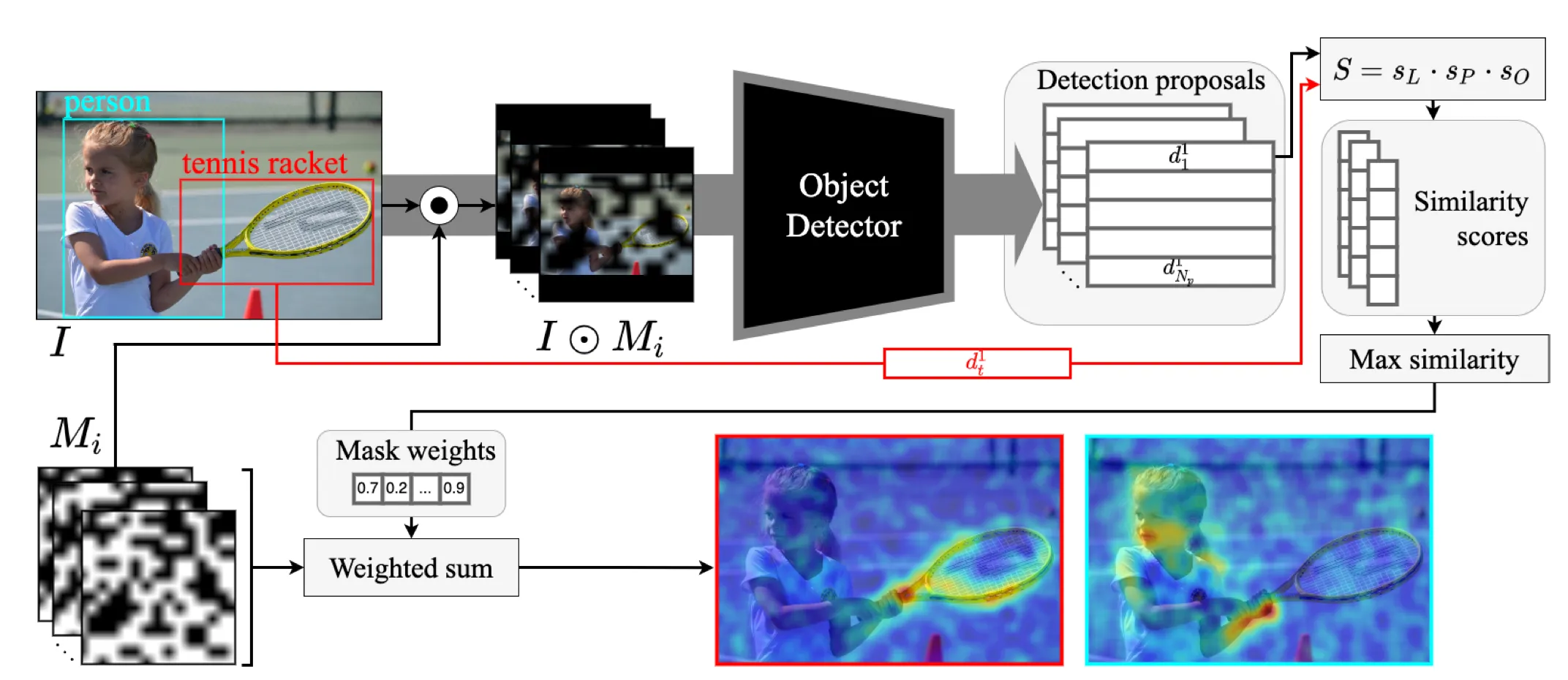
Source
Let’s take a closer look at the D-Rise algorithm step by step:
- D-Rise answers the question of which parts of an image contribute to detecting a particular object. So, first of all, you need to select a picture and a specific object;
- D-Rise addresses this question by measuring how different perturbations of the input affect the output of the model;
- To do so, D-Rise applies many different masks to the initial input and feeds the masked images through the detector. As a result, the model returns a set of detection proposal vectors for each masked image;
- To compare the detection that D-Rise tries to explain and every detection proposal vector produced by the model, D-Rise uses a special metric called similarity score;
- Each mask's similarity scores are computed with this metric, and the saliency map is calculated as the weighted sum of masks. This approach works because only when the mask preserves some important area would the object still get detected, and the mask would get a high score. So, with the weighted sum, D-Rise makes sure that there will be high values on the saliency map only in the important areas;
- D-Rise returns the saliency map.
Similarity score
As mentioned above, the D-Rise concept is based on a so-called similarity score explicitly developed for this algorithm. In short, the similarity score is computed using the similarities between three individual components such as:
- Intersection over Union between the ground truth and predicted bounding box;
- Cosine similarity between the ground truth and predicted class distribution;
- Objectness value of the proposal.
These values are multiplied to calculate the similarity score between any two vectors. As you might notice, such a metric ensures that if any of the factors is close to zero, the similarity value will also be close to zero.
Still, to get a deeper understanding of the similarity score and D-Rise algorithm in general, please check out the initial paper.
D-Rise visualized

Source