Semantic Segmentation Assistant
One of the core pillars of all Hasty is AI-powered annotation. With Hasty focusing on the vision AI field, it brings various best-in-class labeling automation tools for many Computer Vision tasks. One of these options is the Semantic Segmentation AI assistant.
Semantic Segmentation AI assistant (SS AI assistant) focuses on comprehensive annotation automation for a Semantic Segmentation task. This means that the assistant automates:
Labeling each pixel on an image according to target classes;
And creating a segmentation map of the whole image.
Such an approach offers an exponentially quicker way of preparing data for Semantic Segmentation at scale.
How to use the Semantic Segmentation AI assistant?
The Semantic Segmentation AI assistant will not be available when you start a new project. This is because the underlying model first needs data to train on before it starts performing. That data is the annotations that are made in a project. We begin training the tool after you have set 10 images to "Done" or "To review".
You will get a corresponding notification once the tool is ready to work.
To select the assistant, please navigate to the Annotation Environment and press the following icon:

or you can use a hotkey and simply press “S” while in the Annotation environment.
When selected, the assistant will produce annotation suggestions that will look like segmentation shapes with a dotted border.
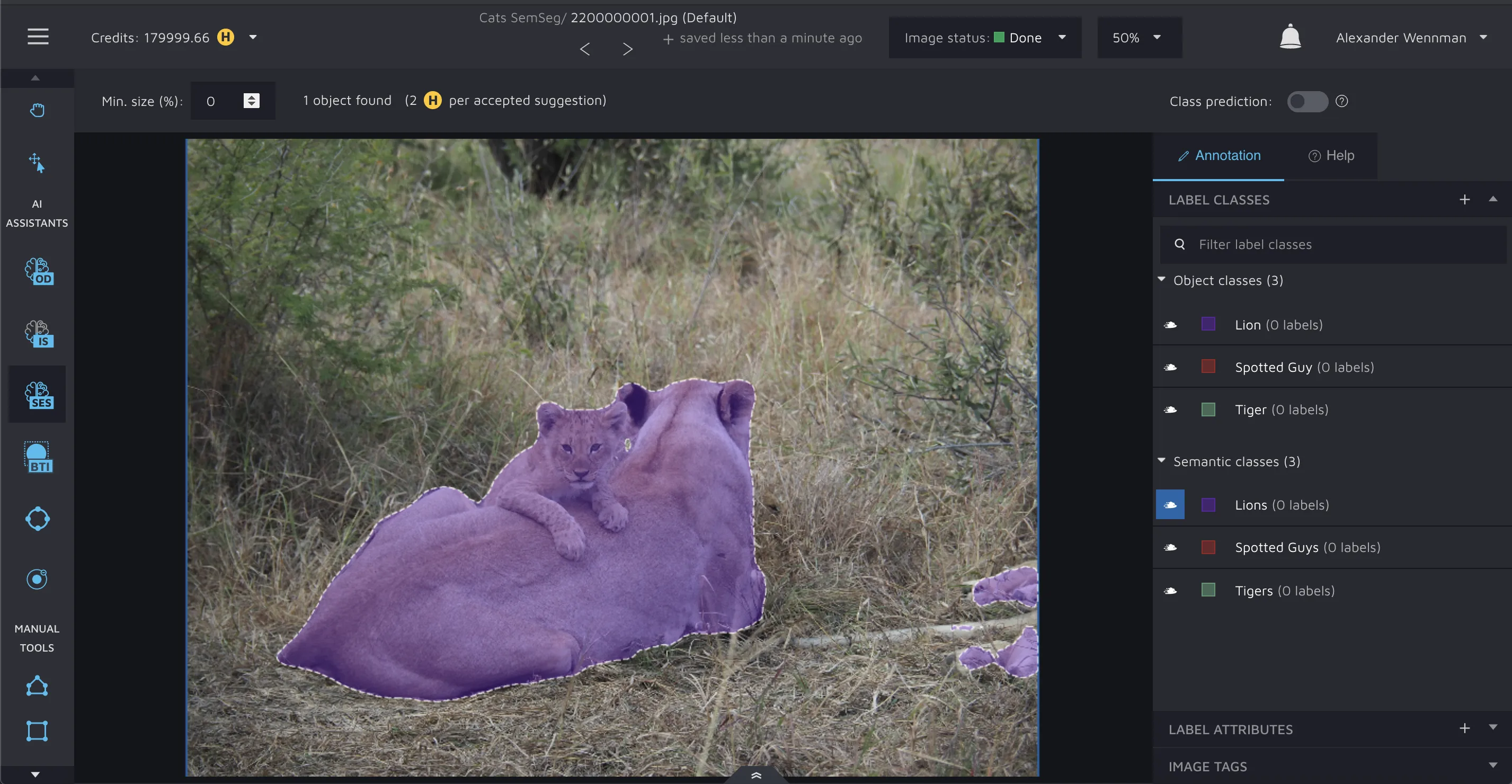
Please notice that these shapes can have different colors. The colors are the same as in your label classes but more transparent. So, the assistant's output can be interpreted as the potential shape of each semantic object the model has found in your image and the label class for each object.
As a user, you only have to accept the algorithm’s suggestion if you think they are good enough. You can do this by left-clicking on the shape you want to approve.
You can also accept all suggestions by pressing "Enter".
If you do not see any shapes or they are not covering the objects as you want, please try adjusting the model’s confidence modifier.
Check out our Getting Start with Hasty tutorial to see the assistants in practice before starting a new project.
Improving AI-powered assistance over time
The first results from our assistants might underwhelm you. This is perfectly normal. What makes Hasty different is that our AI assistants improve the more data they see. After 10 images, you might have a 10% assistance rate (percentage of annotations created by assistants). This is fine. When you've annotated 100 images, it might be 40-65%. When you have thousands of pictures annotated, we can offer remarkably high percentages of automation - everything from 98% to 92% - depending on the use case.
The models retrain after having seen 20% more data. That means a new training is initialized after 12, 15, 19 images, etc.
Confidence parameter
This modifier controls which potential segmentation masks are shown. The higher the confidence value, the fewer potential shapes you see, but those shapes are the ones that our model is the most confident in. The modifier can be changed by adjusting the value in the tool settings bar or by using the hotkeys “,” and “.”.