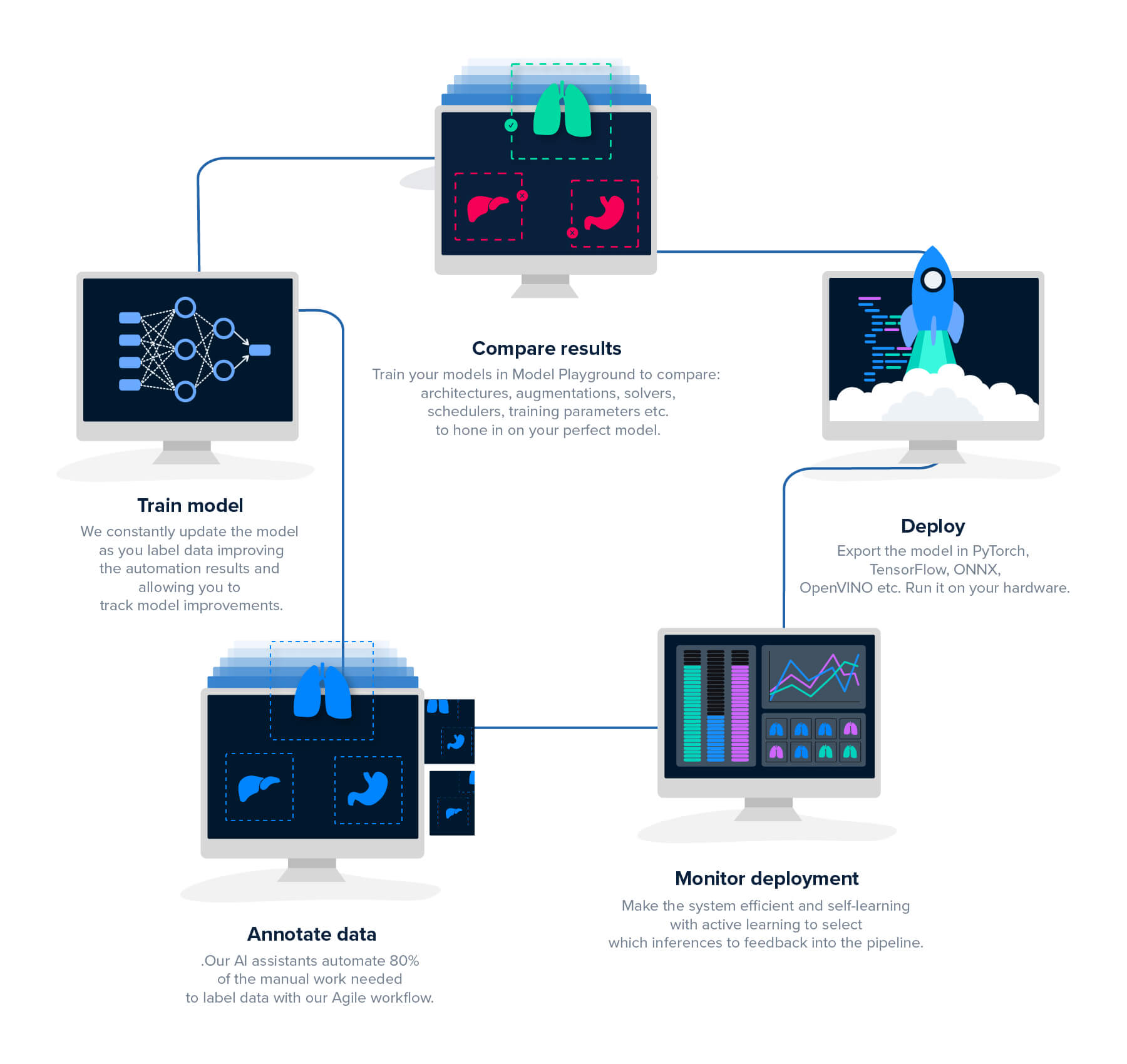
The Hasty platform is a one-stop, data-centric development tool, from the first annotation to a production-ready model. No more complicated integrations or moving data around multiple environments. Our platform makes it simple to build advanced applications.
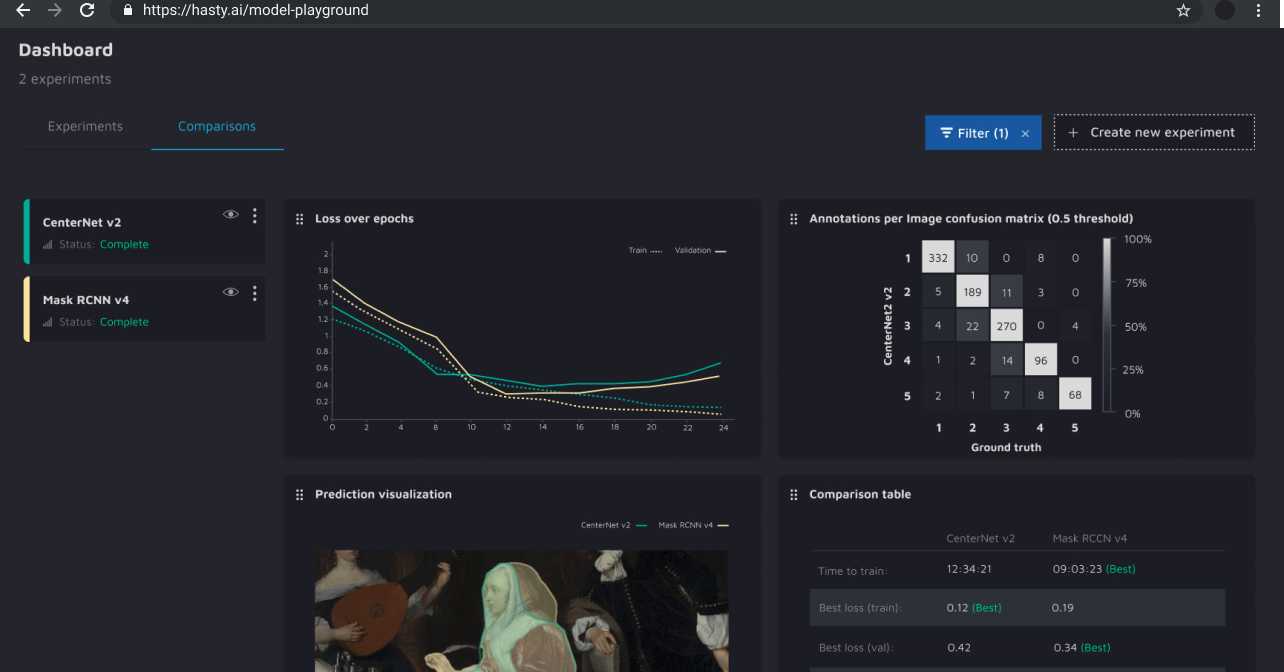
Most ML engineers spend significant time building integrations, moving data between different tools, and keeping track of local experiments in spreadsheets. With the Hasty platform, everything needed is contained in a single application. Train experiments, compare results, parameters, and metrics, and export production-ready models - all in one interface.
In the platform’s Model Playground, your team can experiment with several SOTA architectures and various parameters to see what works best. The platform handles the time-intensive task of ML Ops, so you can discover what works best faster than ever before.

Simple to use doesn’t have to mean overly simplistic. You know your use case the best and we don’t want to limit what you can do. Within the Hasty platform, everything is configurable so we can match 1:1 the configuration of any architecture you use.

Before discovering Hasty, labeling images was labor intensive, time-consuming, and less accurate. Hasty’s approach of training the model while labeling with faster annotate-test cycles has saved Audere countless hours.
Hasty.ai helped us improve our ML workflow by 40%, which is fantastic. It reduced our overall investment by 90% to get high-quality annotations and an initial model.
Because of Hasty, PathSpot has been able to accelerate development of key features. Open communication and clear dialog with the team has allowed our engineers to focus. The rapid iteration and strong feedback loop mirrors our culture of a fast-moving technology company.
